![]() C#
- Async e Await - Embaixo do Capô - I
C#
- Async e Await - Embaixo do Capô - I
 |
Hoje voltamos a tratar da programação assíncrona com async e await no C#. |
Muitos aplicativos possuem funcionalidades que exigem que, por um motivo ou outro, se aguarde a conclusão de uma tarefa que pode ser um processo, um cálculo, uma solicitação da Web ou alguma outra operação de entrada/saída.


Em vez de esperar de forma síncrona pela conclusão de tal operação, o que pode ser ineficiente e fazer com que seu aplicativo pareça que esta travado, é um requisito comum executar essa espera de forma assíncrona, de modo que seu aplicativo permaneça responsivo e capaz de fazer outras coisas durante a espera.
Na linguagem C#, usar async e await é a principal maneira de fazer essa espera assíncrona, e neste artigo o vamos tratar este assunto.
Concorrência não é Paralelismo
Esses dois assuntos muitas vezes se confundem, mas estão longe de ser a mesma
coisa, e entender as diferenças é essencial para o nosso assunto aqui. Vamos nos
aprofundar nas diferenças entre esses conceitos.
Imagine que você tem uma equação muito complexa que pode ser dividida em duas
partes menores e precisa escrever um programa para resolver essa equação. Como
as equações podem ser divididas não faz sentido esperar a parte 1 ser concluída
para você acionar o cálculo da parte 2. No mundo ideal, o correto seria
calculá-las ao mesmo tempo. Mas isso só é possível se você tiver um processador
com mais de 1 núcleo e aqui está o porquê.
Os sistemas operacionais possuem o que chamamos de Agendador de Tarefas. O dever
do Agendador de Tarefas é fornecer tempo de CPU para cada processo.
Um processo é uma instância de um programa sendo executado e cada processo é
subdividido em threads. As Threads são conjuntos de instruções/código que
serão executados pelo escalonador em um determinado momento.
Houve uma época quando os processadores costumavam ter apenas um único núcleo e
ainda assim tudo parecia estar rodando ao mesmo tempo, como isso poderia ser
possível? Acontece que o Agendador de Tarefas é realmente eficiente na
distribuição de tempo e as fatias de tempo são muito, MUITO curtas, então
parecia que tudo estava rodando paralelamente, mas não estava, era só uma atrás
da outra em um ritmo muito rápido .
Tudo bem, mas se cada fatia de tempo é muito curta o que acontece se meu
conjunto de instruções não terminar nesse período de tempo ?
A thread é suspensa e o tempo de CPU é passado para a próxima.
Quando isso ocorre é possível que algumas variáveis que estão sendo alocadas
dentro do cache da CPU precisem ser liberadas para dar espaço para as variáveis
dessa nova thread e isso causa um overhead.
Quanto mais processos você tiver, mais vezes essa operação acontecerá. Essa é
uma das razões pelas quais o computador fica lento quando você tem muitos
programas em execução e apenas um único núcleo para lidar com tudo.
O algoritmo geralmente usado para gerenciar todas essas coisas é chamado de
Round-Robin e o processo de colocar outra thread
para executar é chamado de alternância de contexto.
Voltando ao nosso cálculo, se tivéssemos um processador single-core, mesmo que
dividíssemos o cálculo em duas threads, como vimos, elas ainda seriam executadas
sequencialmente. Para ter um paralelismo real, você precisa ter mais de um
núcleo, para que cada núcleo possa executar o código de forma independente e ao
mesmo tempo (de verdade).
Com isso acho que deu para entender que : Concorrência é diferente de
paralelismo; eles podem ser usados juntos, mas estão longe de ser a mesma coisa.
Paralelismo é fazer mais de uma coisa ao mesmo tempo, simultaneidade ou
concorrência é fazer outra coisa enquanto outra pessoa faz algo que você está
esperando.
Vamos imaginar que temos um computador single-core
rodando um programa C# que criamos, e, esse programa consiste em um leitor de
arquivo de texto com uma interface do usuário simples.
Iniciamos o programa e até digitarmos algo o programa fica ocioso já que não
temos nada sendo executado, a seguir digitamos o caminho do arquivo.
A ação de digitação requer atividade de código para mostrar o que digitamos em um campo de entrada, portanto, há código sendo executado nessa thread.
A seguir clicamos
para abrir o arquivo, e o Sistema Operacional va procurar esse arquivo e nos
fornecer o conteúdo em bytes que precisamos analisar e mostrar na tela.
Supondo que estamos usando uma chamada de sistema operacional
síncrona, estaríamos terminando com algo parecido
como a figura abaixo :
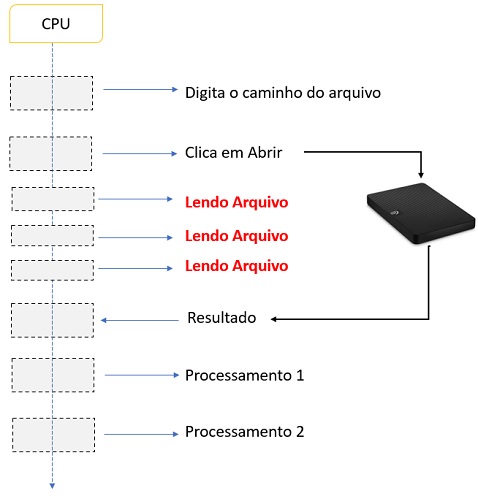
Observe que, enquanto o SO está lendo os dados do disco, nossa thread ainda está em execução, mas na verdade nenhum código está sendo executado, pois estamos apenas esperando que o SO retorne o conteúdo.
A thread está bloqueada e não estamos fazendo nada com esse tempo de CPU, e isso não é bom, certo?
Na verdade, é um
pouco pior pois nosso programa ficará totalmente sem resposta a qualquer tipo de
entrada (teclado ou mouse), pois nossa thread está aguardando a resposta e não
pode fazer mais nada. É como você ficar olhando e esperando a água ferver e não
fazer nada até que isso aconteça.
Se usarmos computação assíncrona, estaríamos executando esta tarefa como
representada no diagrama abaixo :
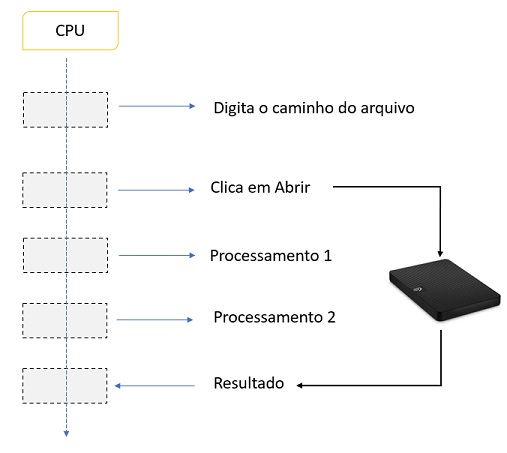
Agora o que acontece aqui é o o seguinte:
1- Pedimos o conteúdo do arquivo e enquanto o SO o procura liberamos a thread responsável pela chamada para fazer outras coisas.
2- Quando o sistema operacional obtiver todos os dados, um retorno de chamada será evocado e a execução do código continuará e o texto será exibido.
Essa abordagem
tornará a interface do usuário responsiva, pois a thread pode processar entradas
do teclado ou movimentos do mouse enquanto aguarda a resposta do sistema
operacional.
Esta abordagem foi chamada de assíncrona porque enquanto esperamos que algo
aconteça podemos fazer outra coisa. Sempre que estivermos executando um processo
não limitado pela CPU, é uma boa ideia usar a programação assíncrona.
Antes de nos aprofundarmos em como funciona o assíncrono, vamos falar um pouco
mais sobre threads, mais especificamente sobre o
ThreadPool.
ThreadPool
Geralmente em um processo .NET, a quantidade de threads está diretamente
relacionada ao número de núcleos do processador que você tem disponível, um
simples 1 para 1. Mas se o .NET achar que mais threads são necessários para o
bom desempenho do sistema, ele criará mais threads por si só e esses threads
farão parte do ThreadPool.
O ThreadPool é uma coleção de longa duração de
threads disponíveis para executar tarefas. A razão para esses threads serem
colocadas em uma coleção de longa duração é possibilitar a reutilização dessas
threads.
Quando uma tarefa ou task atribuída a uma thread for concluída, esta thread é
colocada novamente no ThreadPool para ser reutilizada em uma execução futura
Criar uma thread é uma tarefa de computação cara e elas também ocupam alguns
megabytes de memória, então uma grande quantidade de threads é tão ruim quanto
uma pequena quantidade delas, é por isso que é sempre bom contar com o mecanismo
do ThreadPool que sabe como ajustar essas coisas,
em vez de criar muitas threads explicitamente e cruzar os dedos esperando
que tudo de certo.
Pense em uma Web API, se nosso servidor web tiver apenas dois núcleos, teremos
duas threads, mas o que acontecerá se tivermos 2 requisições em execução e uma
terceira for acionada ?
O .NET notará que
nossas 2 threads estão ocupadas e criará outra para lidar com a requisição. Se
usarmos programação assíncrona, a chance dessas 2 threads serem totalmente
bloqueadas é muito menor, pois o processo que consome mais tempo costuma ser
relacionado a I/O e a operação de I/O não está mais bloqueando as threads
existentes.
Você poderia argumentar que hoje em dia a maioria dos computadores tem muitos
núcleos e eles podem lidar com cargas pesadas dividindo o processamento entre
esses núcleos. Na verdade, eles são muito poderosos, mas ultimamente, começamos
a usar cada vez mais uma tecnologia que depende quase de ambientes de núcleo
único: Containers. Os contêineres tendem a ser
single-core e, nesse cenário, ter um ThreadPool bem
dimensionado é essencial, tornando a programação assíncrona crucial para o bom
desempenho do seu aplicativo.
Agora que demos uma olhada em Threads e no ThreadPool,
é hora de entender as Tasks ou Tarefas.
Tasks
Basicamente, podemos considerar uma Task ou Tarefa um trabalho a ser executado.
Imagine que temos um departamento onde você e um amigo são responsáveis por ir
até o arquivo e solicitar um documento específico para a pessoa que gerencia o
setor de arquivo. Você tem um supervisor que conversa com esses clientes,
preenche um requisito e entrega para você.
O cliente 1 chegou. Seu supervisor conversa com o cliente, recebe o pedido,
preenche o requisito formal e ao ver você e seu amigo, ele escolhe
aleatoriamente um de vocês para ir ao arquivo buscar o que precisa.
Neste cenário, temos o seguinte :
1- O cliente é um pedaço de código que solicita alguns dados (E/S);
2- O supervisor é o ThreadPool que gerencia as
threads e despacha o trabalho (Tasks) a ser feito;
3- As threads são você e seu amigo. Vocês são os
trabalhadores esforçados, aqueles que realizarão a Task ou Tarefa dada;
4- A Task ou Tarefa é um trabalho que será
executado pela thread (você). Neste caso, dirija-se ao setor de arquivo e
solicite um documento ao responsável.
O bom é que o
ThreadPool pode receber várias tarefas e as tarefas serão despachadas à medida
que as threads forem disponibilizadas. Se o ThreadPool ficar com muitas tarefas
pendentes, um novo funcionário pode ser contratado para entrar na sua equipe e
aumentar a performance, mas só se valer a pena, contratar (criar uma nova
thread) sai caro :)
Quando você volta do setor de arquivamento, você não volta apenas com o
documento, você volta com a exigência da tarefa. Nesse requisito, você tem
alguns dados como o ID dessa Tarefa e seu Status. Anexado a este requisito você
tem o resultado desta tarefa, nesse caso, um documento (ou nenhum documento
se não foi encontrado).
Por isso Task tem
um parâmetro Generic, sempre retorna um Task de alguma coisa (se você espera
um valor de retorno do método). Para sua pesquisa no departamento de
arquivamento, seria um Task<Document>.
Agora você tem o documento para devolver ao seu cliente. Basta chamá-lo na sala
de espera, já que seu cliente solicitou uma tarefa assíncrona, ele não ficará no
balcão esperando você pegar o documento dele. Em breve descobriremos como chamar
seu cliente para entregar o pedido, próximo da fila, por favor.
Agora que também temos Tasks, é hora de entender o
fluxo de trabalho de um código assíncrono.
Tornando-se assíncrono
Vamos obter o conteúdo da task que você executou usando o código abaixo:
var conteudo = File.ResultAllTextAsync("Documento.txt")
|
Como podemos ver o
método não retorna uma string, ele retorna uma Task com uma string que pode
conter conteúdo.
Se você usar o Intellisense do VisualStudio verá dois métodos que
retornarão a string de resultado: .Wait() e .Result().
NÃO use esses
métodos, eles são métodos de bloqueio e seu código não será executado de forma
assíncrona.
Se você executar seu trabalho de forma assíncrona, enquanto o responsável pelo
arquivamento procura um documento, você pode voltar e pegar uma nova tarefa para
entregar a outra pessoa do departamento de arquivamento.
Usar
.Wait() ou .Result() implicará em você esperar que
a pessoa olhe todo o arquivo até encontrar (ou não) o documento e
devolvê-lo a você.
Vamos ver uma maneira de executar isso de forma assíncrona usando o código a
seguir:
public Task<string> GetDocumento()
{
var content = File.ReadAllTextAsync(@"Documento.txt")
.ContinueWith(t =>
{
return t.Result;
});
return content;
}
|
O método
ContinueWith() recebe uma
Action<Task<string>> que será disparada apenas quando a Task for
concluída, nesse caso, quando você retornar com o requisito formal e o
documento.
Mas o que acontece se o documento não for encontrado ?
Nesse caso, seu cliente receberá uma resposta vazia, pois esse código não lida com Exceções. Para lidar com eles, você deve implementar isso manualmente:
|
public Task<string> GetDocumento() { var content = File.ReadAllTextAsync(@"Documento.txt") .ContinueWith(t => { if (t.IsFaulted) { Console.WriteLine(t.Exception); } return t.Result; }); return content; } |
Tudo bem, agora temos isso funcionando, mas o código pode ser melhorado. Temos muitas linhas de código apenas para ler um arquivo.
É por isso que na versão 5.0 do C# foram introduzidas as palavras chaves async/await.
No exemplo a seguir, não apenas imprimimos o resultado, mas o recuperamos e o retornamos. Fazer algo assim usando o código assíncrono à moda antiga é muito difícil, pois temos muitos problemas de sincronismo. Usando a nova maneira de fazer as coisas, nosso código fica assim.
|
public async Task<string>
GetDocumento() { return await File.ReadAllTextAsync("Documento.txt"); } |
Bem melhor, não é memos ?
Observe que a assinatura do método mudou de public Task<string> para public async Task<string> e agora temos a palavra-chave await após a instrução return.
Por que isso acontece?
Porque agora muita
coisa está acontecendo debaixo do capô e é isso que veremos na próxima parte do
artigo ...
![]()
"E vi um novo céu, e uma nova terra. Porque já o primeiro céu e a primeira
terra passaram, e o mar já não existe."
Apocalipse 21:1

Referências:
NET - Unit of Work - Padrão Unidade de ...
http://msdn.microsoft.com/en-us/library/vstudio/hh156513.aspx