![]() ASP.NET
Core - Implementando Onion Architecture com CQRS - I
ASP.NET
Core - Implementando Onion Architecture com CQRS - I
 |
Hoje vamos realizar a implementação da Onion Architecture em uma aplicação ASP .NET Core aplicando o CQRS. |
A Onion Architecture ou arquitetura Cebola, foi definida por Jeffrey Palermo com o objetivo de criar aplicações fracamente acopladas e fáceis de manter. Ela lembra as camadas que vemos quando cortamos uma cebola que podem ser separadas facilmente. Da mesma forma, as camadas da Onion Architecture são separáveis, pois são fracamente acopladas, e isso fornece uma arquitetura altamente testável.
  |
Recordando o que é a Onion Architecture
Na Arquitetura Cebola, existem camadas concêntricas separáveis de códigos, de modo que a camada mais interna é totalmente independente das outras camadas. Geralmente temos 3 camadas nesta arquitetura :

O Domain é a camada mais interna, enquanto Infrastructure + Presentation é a camada mais externa.
As camadas na Arquitetura Cebola na ASP .NET Core
Ao criar uma aplicação ASP .NET Core seguindo os princípios da Arquitetura Cebola você poderia ficar em dúvida em como criar as camadas.
Quais deveriam ser as principais camadas da Onion Architecture e como elas se comunicam entre si ?
Veremos isso a seguir.
Em seu aplicativo ASP.NET Core, a aplicação da arquitetura Onion Architecture pode ser feita criando 3 camadas :
A camada Domain
Esta camada esta no centro da arquitetura e não depende de nenhuma outra camada.
Esta camada contém a lógica do negócio e as Entidades que são comuns a todo o aplicativo e podem ser compartilhadas por outros projetos. Suponha que você esta construindo um aplicativo para uma Escola, então provavelmente você vai criar entidades definidas em classes como : Aluno, Professor, Curso, etc.
Camada
Application
Esta camada contém interfaces que serão implementadas pelas
camadas externas da Onion Architecture, como
Infrastructure + Presentation.
Para o aplicativo Escola, podemos adicionar uma interface que lida com operações de banco de dados para as entidades como Aluno, Professor e Curso. Essa interface pode ser implementada na camada de infraestrutura, onde as operações reais do banco de dados são adicionadas. (temos aqui o Princípio de Inversão de Dependência.)
Isso ajuda na construção de aplicativos escaláveis, pois podemos adicionar novas interfaces para lidar com autorizações de envio de SMS/Email, por exemplo. A seguir podemos implementar essas interfaces na camada de infraestrutura. Desta forma, se for necessário, podemos facilmente alterar as implementações das interfaces na camada de infraestrutura sem afetar a camada de Domain e Application.
O que é o princípio de inversão de dependência ?
O Princípio de Inversão de Dependência (DIP) afirma que os módulos de alto nível não devem depender de módulos de baixo nível. Criamos interfaces na camada Application e essas interfaces são implementadas na camada de infraestrutura.
Em vez de fazer com que o Core dependa do acesso a dados e outras questões de infraestrutura, invertemos essas dependências, portanto, a Infraestrutura e a Apresentação dependem do Core. Isso é obtido adicionando abstrações, como interfaces ou classes base abstratas, à camada Application. As camadas fora do Core, como Infraestrutura, implementam essas abstrações.
Um bom exemplo é a implementação do
padrão Repositório. Dentro desse design, primeiro adicionaríamos uma
interface IRepository à camada
Application. Em seguida, implementaríamos essa
interface na Infrastructure criando uma classe
Repository usando nossa tecnologia de acesso a
dados preferida. Finalmente, dentro do Core, a
lógica que escrevemos usará apenas a interface IRepository,
então o Core permanecerá independente das questões
de acesso aos dados.
As camadas de Domain e Application são conhecidas
como camadas principais da arquitetura Cebola, ou seja o
Core da aplicação.
Camada Infrastructure + Presentation
As camadas de infraestrutura e
apresentação são as camadas mais externas da Onion Architecture.
Na camada de infraestrutura, adicionamos códigos de nível de infraestrutura,
como Entity Framework Core para operações de banco de dados, Tokens JWT para
autenticação e outras operações semelhantes. Toda a tarefa pesada do aplicativo
é realizada nesta camada.
A camada de apresentação terá um projeto que o usuário utilizará. Pode ser um
projeto do tipo Web API, Blazor, React ou MVC. Observe que este projeto também
conterá as interfaces de usuário.
Como a camada de apresentação está fracamente acoplada a outras camadas, podemos
alterá-la facilmente. Assim uma camada de apresentação usando
React pode
ser facilmente alterada para um projeto Blazor WebAssembly.
Onion Archictecture x Clean Architecture
Se você conhece a Clean Architecture pode estar se perguntando se a Onion Architecture é diferente da Clean Architecture ?
Na verdade, Clean Architecture é apenas
um termo que descreve a criação de uma arquitetura onde as camadas estáveis não
dependem de camadas menos estáveis. Já sabemos que a camada de domínio é a
camada estável e não depende das camadas externas.
Isso significa que a Onion Architecture é uma arquitetura limpa.
Os principais pontos para identificar uma arquitetura limpa são:
Onion Archictecture x N-Camadas
Como a Onion Architecture difere da arquitetura N-Camadas ou N-Tier ?
A Onion Architecture é uma arquitetura limpa, enquanto o N-Tier não é uma arquitetura limpa.
A arquitetura N-Tier não é uma arquitetura escalonável. Se você vir o diagrama fornecido a seguir da arquitetura N-Tier, verá que há três camadas - Presentation, Bussiness, Data Access (Apresentação, Negócios e Acesso a dados) :

O usuário interage com o aplicativo a partir da camada Apresentação, pois contém a IU. A camada de negócios contém a lógica de negócios enquanto a camada de acesso a dados interage com o banco de dados. A camada de acesso a dados geralmente contém um ORM como Entity Framework core ou Dapper.
Ao criar um projeto usando uma arquitetura de N- Camadas, as camadas dependem umas das outras e acabamos construindo uma estrutura altamente acoplada, e, isso vai contra o propósito de uma Arquitetura Limpa.
Considerações importantes
a serem usadas para implementar a arquitetura Cebola
(adaptado do original:
https://www.ssw.com.au/rules/rules-to-better-clean-architecture)
1- Manter o Domain independente da Infrastructure
A camada de domínio deve ser
independente das questões de acesso aos dados. A camada de domínio deve mudar
apenas quando algo dentro do domínio muda, não quando a tecnologia de acesso a
dados muda. Isso garante que será mais fácil manter o sistema no futuro, pois as
alterações nas tecnologias de acesso a dados não afetarão o domínio e
vice-versa.
Isso costuma ser um problema ao construir sistemas que usam o Entity Framework,
pois é comum que anotações de dados(Data
Annotations) sejam adicionadas ao modelo de domínio. As anotações de
dados, como os atributos Required ou MinLength,
oferecem suporte à validação e ajudam o Entity Framework a mapear objetos no
modelo relacional.
Neste exemplo abaixo temos o uso das Data Annotations em um modelo de domínio aplicado a uma entidade Customer:
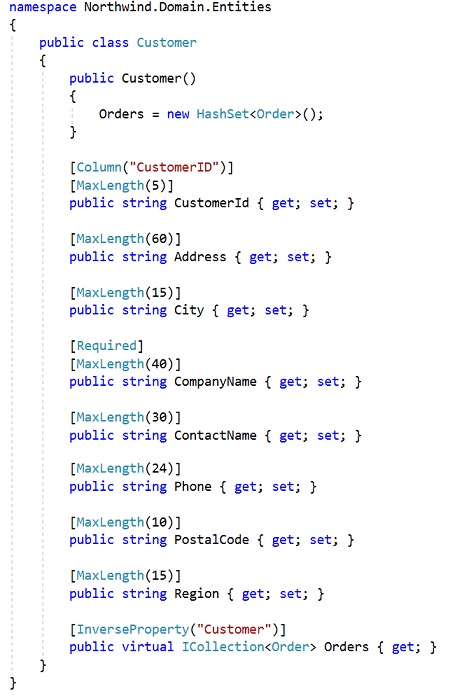
Neste exemplo o domínio está cheio de anotações de dados. Se a tecnologia de acesso a dados mudar, provavelmente precisaremos mudar todas as entidades, pois todas as entidades terão anotações de dados.
A seguir, vamos remover as anotações de dados da entidade Customer e, em vez disso, usaremos um tipo de configuração especial em um arquivo separado:

Abaixo estamos definindo as configurações usando a Fluent API em um arquivo separado :

Agora a entidade Customer esta enxuta e a configuração pode ser adicionada à camada de persistência, completamente separada do domínio. Dessa forma, temos que o domínio esta independente das questões de acesso aos dados.
2- Manter a lógica do negócio fora da camada de apresentação
Não é raro que a lógica de negócios esteja adicionada diretamente à camada de apresentação.
Ao construir aplicações ASP.NET Core MVC, isso normalmente significa que a lógica de negócios é adicionada aos controladores de acordo com o seguinte exemplo:

A lógica usada no controlador acima não pode ser reutilizada, por exemplo, por um aplicativo console. Isso pode ser bom para sistemas triviais ou pequenos, mas seria um erro para sistemas corporativos.
É importante garantir que uma lógica como essa seja independente da IU para que o sistema seja fácil de manter agora e no futuro. Uma ótima abordagem para resolver esse problema é usar o padrão CQRS com Mediator.
A sigla CQRS
significa realizar a separação clara entre comandos (operações de gravação)
e consultas (operações de leitura). O CQRS pode ser usado com
arquiteturas complexas, como Event Sourcing, mas os
conceitos também podem ser aplicados a aplicativos mais simples com um único
banco de dados.
A MediatR é uma biblioteca .NET de código aberto de
Jimmy Bogard que fornece uma abordagem elegante e poderosa para escrever
CQRS, tornando mais fácil escrever código limpo.
Para mais detalhes sobre CQRS com MediatR leia o meu artigo : Usando o padrão Mediator com MediatR (CQRS)
3- Usar corretamente DTOs e View Models
Os Objetos de transferência de dados (DTOs) e as View Models não são o mesmo conceito !
A principal diferença é que, embora as
View Models possam encapsular o comportamento, os DTOs não podem.
O objetivo de um DTO é a transferência de dados de uma parte de um aplicativo
para outra. Uma vez que os DTOs não encapsulam o comportamento, eles podem ser
facilmente serializados e desserializados em outros formatos, por exemplo, JSON,
XML e assim por diante.
O objetivo de uma View Model também é a
transferência de dados, no entanto, as VMs podem encapsular o comportamento.
Este comportamento é útil, por exemplo, ao criar um aplicativo
WPF + MVVM, mas não tão útil ao criar um SPA - já que você não pode
serializar o comportamento e passá-lo da ASP.NET Core MVC para o cliente.
4- Validar corretamente os Solicitações(Requests) do cliente
A criar aplicações ASP .NET Core Web APis, é importante validar cada solicitação para garantir que atenda a todas as pré-condições esperadas.
O sistema deve processar solicitações válidas, mas retornar um erro para todas as solicitações inválidas. No caso de controladores ASP.NET, essa validação pode ser implementada da seguinte forma:

No exemplo acima, temos um mau exemplo de validação, pois a validação ModelState(do estado do modelo) é usada para garantir que a solicitação seja validada antes de ser enviada usando MediatR.
Tenho certeza de que você está se
perguntando - por que este é um mau exemplo ?
![]()
Porque, no caso da criação de produtos, queremos validar todas as solicitações de criação de um produto, não apenas aquelas que vêm por meio da Web API.
Por exemplo, se estamos criando produtos
usando um aplicativo Console que invoca o comando diretamente, precisamos
garantir que essas solicitações também sejam válidas. Portanto, a
responsabilidade pela validação de solicitações não pertence à Web API, mas sim
a uma camada mais profunda, idealmente logo antes de a solicitação ser acionada.
Uma abordagem para resolver esse problema é mover a validação para a camada
Application, validar imediatamente antes que a solicitação seja executada.
No caso do exemplo acima, isso poderia ser implementado da seguinte forma:
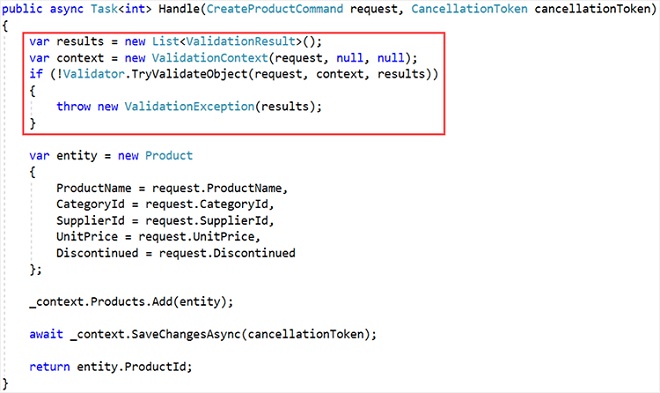
A implementação acima resolve o problema. Se a solicitação se originar da Web API ou de um aplicativo Console, ela será validada antes de ocorrer o processamento posterior. No entanto, o código acima é clichê e precisará ser repetido para cada solicitação que requer a validação. E, só funcionará se o desenvolvedor se lembrar de incluir a verificação de validação em primeiro lugar!
Felizmente, se você está seguindo nossas recomendações e combinando CQRS com MediatR, você pode resolver este problema incorporando o código que usa a classe RequestValidationBehavior:

Esta classe RequestValidationBehavior validará automaticamente todas as solicitações de entrada e lançará uma ValidationException caso a solicitação seja inválida. Esta é a melhor e mais fácil abordagem, pois as solicitações existentes e as novas adicionadas posteriormente serão validadas automaticamente.
5- Saber usar corretamente Value Objects
Ao definir um domínio, as entidades são
criadas e consistem em propriedades e métodos. As propriedades representam o
estado interno da entidade e os métodos são as ações que podem ser executadas.
As propriedades geralmente usam tipos primitivos, como strings, números, datas e
assim por diante.
Como exemplo, considere uma conta AD (Admin) que
consiste em um nome de domínio e nome de usuário: SSW/Macoratti
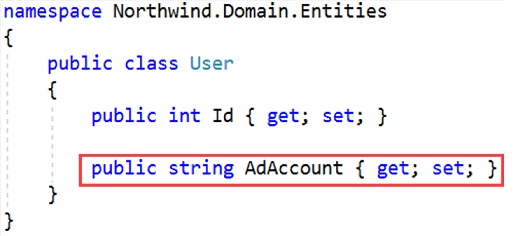
Aqui o nome é uma string, e portanto, usar o tipo string faz sentido. Sim ou não ?
Se analisarmos bem, uma conta AD é um tipo complexo.
Apenas algumas strings são contas AD válidas.
Às vezes, você desejará usar uma representação de string (SSW\Macoratti), às vezes precisará do nome de domínio (SSW) e às vezes apenas do nome de usuário (Macoratti).
Tudo isso requer lógica e validação, e a lógica e a validação não podem ser fornecidas pelo tipo primitivo de string. Claramente, o que é necessário é um tipo mais complexo, como um Value Object ou objeto de valor.
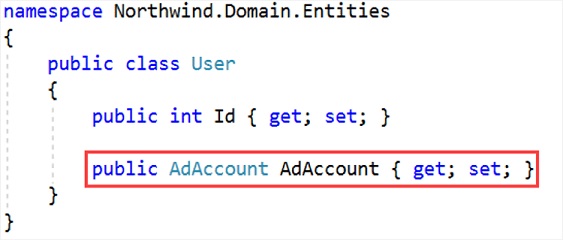
Aqui o tipo AdAccount deverá ser baseado no tipo ValueObject e a seguir temos uma implementação de exemplo para AdAccount:

Agora tratar as contas do AD vai ficar mais fácil. Você pode construir um novo AdAccount com o método Factory For da seguinte maneira:
var account = AdAccount.For("SSW\\Macoratti");
O método Factory
garante que apenas contas válidas do AD possam ser construídas e para sequências
de contas inválidas do AD, as exceções são significativas, ou seja,
AdAccountInvalidException em vez de
IndexOutOfRangeException.
Dessa forma com uma conta nomeada AdAccount, você
pode acessar:
Usando o recurso dos Value Objects temos acesso também a operadores de conversão implícitos e explícitos e dessa forma fica claro os benefícios em usá-los quanto pertinente.
Esses são alguns dos aspectos chaves que você deve considerar ao implementar a arquitetura Cebola para ter uma arquitetura limpa.
Na próxima parte do artigo iremos mostrar um exemplo prático de implementação da arquitetura Cebola.
"Sei estar abatido, e
sei também ter abundância; em toda a maneira, e em todas as coisas estou
instruído, tanto a ter fartura, como a ter fome; tanto a ter abundância, como a
padecer necessidade.
Posso todas as coisas em Cristo que me fortalece."
Filipenses 4:12,13

Referências: