![]() .NET
- RESTful API (panorama)
.NET
- RESTful API (panorama)
 |
Neste artigo vamos rever os conceitos envolvidos na criação de uma RESTful API na plataforma .NET. |
A palavra API é um acrônimo para “Application Program Interface”, e, uma WEB API pode ser usada em vários tipos de aplicativos e atua como uma espécie de mediador entre dois aplicativos.


Se você estiver criando um site, ou um aplicativo de página única (SPA), ou um aplicativo móvel, ou quando precisar se comunicar com um serviço no lado do servidor, ou mesmo se um aplicativo precisar se comunicar com outro aplicativo (por exemplo : um cliente para um servidor), uma API pode ser usada para isso.
Também é possível usar API com Inteligência Artificial, Machine Learning, Cloud, Microservices, Big data, e muitas outras tecnologias. Para projetar uma boa API, existem alguns princípios que podem ser seguidos e neste artigo eu vou procurar apresentar alguns desses princípios.
Protoco HTTP
Antes de começar a falar sobre o REST em si, vou apresentar alguns conceitos sobre o protocolo HTTP.
O protocolo HTTP é usado para se comunicar com o servidor por meio de solicitações e respostas. Por exemplo, no caso de um aplicativo WEB, a interface do usuário fará uma solicitação ao serviço no back-end, o serviço tratará essa solicitação e retornará uma resposta. Este é um exemplo de como o HTTP funciona:

O HTTP é um protocolo que permite a busca de recursos, como documentos HTML sendo a base de qualquer troca de dados na Web e é um protocolo cliente-servidor, o que significa que as solicitações são iniciadas pelo destinatário, geralmente o navegador da Web. Clientes e servidores se comunicam trocando mensagens individuais (em oposição a um fluxo de dados), e, as mensagens enviadas pelo cliente, geralmente um navegador da Web, são chamadas de requisições (requests) e as mensagens enviadas pelo servidor como resposta são chamadas de respostas (responses)
Um request HTTP contém 3 partes:
Um response HTTP contém 3 partes :
Os verbos HTTP
O HTTP define um conjunto de métodos de request para indicar a ação desejada a ser executada para um determinado recurso. Embora também possam ser substantivos, esses métodos de solicitação às vezes são chamados de verbos HTTP.
Os principais verbos HTTP usados são:
GET - Solicita uma representação de um
recurso específico. É usado apenas para retornar dados.
POST - Usado para enviar uma entidade para
um recurso específico. Ele é usado para criar um novo recurso.
PUT - Usado para substituir todas as
propriedades de um recurso. É usado para atualizar um recurso.
PATCH - Usado para aplicar modificações
parciais (quando não é necessário atualizar todo o recurso, mas apenas parte
dele).
DELETE - Usado para excluir um recurso.
Existem outros verbos, mas esses são os verbos mais comuns. Com eles é possível realizar as operações CRUD (Create, Update, Read, Delete).
Status Code
O Status Code ou código de status é retornado na resposta da API. É um número
que representa que tipo de sucesso ou fracasso aconteceu. Quando o cliente faz
uma solicitação para uma API, ele retorna um código de status do servidor após a
solicitação.
A seguir temos alguns dos códigos de status mais comuns :
200 - Ok: Este status significa que a
solicitação foi bem-sucedida.
201 - Created: Este status significa que a
solicitação foi bem-sucedida e um novo recurso foi criado como resultado. Isso
geralmente é retornado após uma solicitação POST.
204 - No Content: Podemos retornar este status
quando não quisermos retornar nada.
400 - BadRequest: Este é um status genérico para
erro. Isso significa que o servidor não conseguiu entender a solicitação devido
à sintaxe inválida.
401 - Unauthorized: Este status significa que o
cliente não está autenticado, devendo ele autenticar para fazer a requisição.
403 - Forbidden: Este status significa que o
cliente está autenticado, mas não tem permissão para fazer o que está tentando
fazer. Ao contrário do 401, a identidade do cliente é conhecida pelo servidor.
404 - Not Found: Este status significa que o
servidor não encontrou o recurso solicitado.
500 - Internal Server Error: Esta é uma resposta
genérica da API REST, significa que o servidor encontrou uma situação que não
sabe como lidar.
503 - Service Unavailable: esse status significa
que o servidor não está pronto para atender a solicitação.
REST - Representation State Transfer
O termo “REST” é um acrônimo para “Representational State
Transfer”, sendo um estilo de arquitetura para fornecer padrões entre
sistemas de computador na web, facilitando a comunicação entre os sistemas.
O REST tem seis restrições de orientação que devem ser satisfeitas se uma interface precisar ser chamada de RESTfull. Estes são os princípios:
Cliente-servidor — A separação de
preocupações é o princípio por trás das restrições cliente-servidor. Ao separar
as preocupações da interface do usuário das preocupações de armazenamento de
dados, melhoramos a portabilidade da interface do usuário em várias plataformas
e melhoramos a escalabilidade simplificando os componentes do servidor. Talvez o
mais significativo para a Web, no entanto, seja que a separação permite que os
componentes evoluam independentemente, suportando assim o requisito da escala da
Internet de vários domínios organizacionais.
Stateless — A comunicação deve ser
stateless por natureza. Cada solicitação do cliente para o servidor deve
conter todas as informações necessárias para entender a solicitação e não pode
aproveitar nenhum contexto armazenado no servidor. O estado da sessão é,
portanto, mantido inteiramente no cliente.
Armazenável em cache — As restrições de
cache exigem que os dados em uma resposta a uma solicitação sejam rotulados
implícita ou explicitamente como armazenáveis em cache ou não. Se uma resposta
puder ser armazenada em cache, um cache de cliente terá o direito de reutilizar
esses dados de resposta para solicitações equivalentes posteriores. Todas as
solicitações feitas devem oferecer suporte à capacidade de cache.
Interface uniforme — Ao aplicar o princípio
de generalidade da engenharia de software à interface do componente, a
arquitetura geral do sistema é simplificada e a visibilidade das interações é
aprimorada. As implementações são dissociadas dos serviços que fornecem, o que
incentiva a evolução independente.
Sistema em camadas — O estilo de sistema em
camadas permite que uma arquitetura seja composta de camadas hierárquicas,
restringindo o comportamento do componente de forma que cada componente não
possa “ver” além da camada imediata com a qual está interagindo.
Código sob demanda (opcional) — REST permite
que a funcionalidade do cliente seja estendida baixando e executando código na
forma de applets ou scripts. Isso simplifica os clientes, reduzindo o número de
recursos necessários para serem pré-implementados. Permitir que os recursos
sejam baixados após a implantação melhora a extensibilidade do sistema. No
entanto, também reduz a visibilidade e, portanto, é apenas uma restrição
opcional no REST.
Desta forma o REST (Representational State Transfer) refere-se a um
grupo de restrições de projeto de arquitetura de software que trazem sistemas
distribuídos eficientes, confiáveis e escaláveis.
A ideia básica do REST é que um recurso, e.g. um documento, é transferido por
meio de interações cliente/servidor bem reconhecidas, independentes de idioma e
padronizadas de forma confiável. Os serviços são considerados RESTful quando
aderem a essas restrições.
As APIs HTTP em geral às vezes são chamadas de APIs RESTful, serviços RESTful ou
serviços REST, embora não necessariamente sigam todas as restrições REST. Os
iniciantes podem assumir que uma API REST significa um serviço HTTP que pode ser
chamado usando bibliotecas e ferramentas da web padrão.
Uma API REST é uma interface de programa de aplicativo (API) que usa
solicitações HTTP para obter ou manipular dados. Na arquitetura REST, o cliente
envia uma solicitação para obter ou modificar recursos e o servidor envia uma
resposta a essas solicitações. Para fazer essas requisições são usados verbos
HTTP.
O termo “Restful” refere-se a uma abordagem
pragmática para usar REST, o que significa que a API da Web aplica os princípios
REST. Não é raro ver uma API que não é completamente RESTful, e o motivo é que é
um pouco difícil aplicar todos os princípios o tempo todo, então é sempre bom
analisar cada situação e não ficar tão restrito nisso. Certifique-se de estar
construindo o melhor para o próprio aplicativo.
Resource
A abstração chave da informação REST é um resource ou recurso.
Qualquer informação que pode ser nomeada pode ser um recurso: um documento ou imagem, um serviço temporal, uma coleção de outros recursos, um objeto não virtual (por exemplo, uma pessoa) e assim por diante. REST usa um identificador de recurso para identificar o recurso específico envolvido em uma interação entre componentes.
Cada URI aponta para um recurso e recurso significa coisas que representam os
objetos em seu sistema, por exemplo: produtos, clientes, livros e assim por
diante. Você também pode pensar em recursos como Modelos/Entidades de
Domínio. São coisas que você deseja obter, inserir, atualizar e excluir.
O conceito fundamental em qualquer API RESTful é o
recurso. Um recurso é um objeto com um tipo, dados associados, relacionamentos
com outros recursos e um conjunto de métodos que operam nele. É semelhante a uma
instância de objeto em uma linguagem de programação orientada a objetos, com a
importante diferença de que apenas alguns métodos padrão são definidos para o
recurso (correspondente aos métodos padrão HTTP GET, POST, PUT e DELETE),
enquanto uma instância de objeto normalmente tem muitos métodos.
Exemplo de API RESTfull
Agora, para ilustrar, vamos apresentar um exemplo de API REST e alguns
princípios que são considerados quando se pensa em RESTfull.
Para este exemplo, vamos considerar um cenário em que é necessário manusear livros. Teremos um endpoint para criar, obter todos os livros, obter um único livro, atualizar e excluir um livro.
Convenções em URIs
No REST, os URIs são o caminho para os recursos, e, para demonstrar alguns
exemplos, vamos supor que estamos executando uma API localmente. Nesse caso, a
URI base seria algo como :
https://localhost:5001/
Após a URI base com o endereço ser especificado, o objeto/recurso, que no caso são os livros, ficaria assim a URI completa: https://localhost:5001/livros
Com base nisso, imagine um cenário em que temos que realizar operações CRUD para lidar com livros usando a convenção RESTful. Neste caso as URIs usadas seriam as seguintes:
GET /api/livros (para obter todos os
livros)
GET /api/livros/1 (para obter um único livro
pesquisando por id 1)
PUT /api/livros/1 (para atualizar um livro
com id 1)
DELETE /api/livros/1 (para excluir um livro
com id 1)
POST /api/livros (para criar um livro)
Observe que cada endpoint contém um verbo HTTP, seguido por
“/api” e “/livros”.
Se estivéssemos trabalhando com “cliente” ao invés de “livro”, seria:
“/api/clientes/”. Isso é uma convenção. Também para cada operação, é utilizado
um VERBO HTTP específico (ex.: GET, POST, DELETE, ou outro).
Substantivos são preferíveis quando trabalhamos com APIs RESTful. Portanto, em
vez de usar verbos no design das APIs, devemos usar substantivos. Por exemplo,
em vez de ter algo como /getLivros e /deleteLivro,
será: /livros, e o verbo HTTP especificará
qual tipo de operação será aplicada. Em geral também é preferível usar o plural
(livros ao invés de livro), a não ser nos casos que
se tratará de um único item, por exemplo livro/título,
caso em que será devolvido um único livro.
Na URI, também algum identificador único deve ser usado porque cada URI deve
apontar para um recurso específico. Na lista de endpoints acima, o id do livro
está sendo utilizado em algumas operações (Get, Put e Delete), mas não é
obrigatório o uso do id, também pode ser algum outro identificador único.
Também é possível usar strings de consulta para propriedades que não são de recursos. Geralmente são utilizados elementos como formatação, ordenação, busca, entre outros. Eles são strings de consulta porque não fazem parte do próprio URI, são sobre argumentos opcionais para essas URIs ou para esses recursos. Por exemplo, podemos ter algo como : /livros?sort=titulo ou /livros?page=2, ou outros.
APIs idempotentes
Uma API REST deve ser idempotente. Idempotente
significa “operação que pode ser aplicada várias vezes sem alterar o
resultado”. Isso significa que as operações executadas pela API sempre devem
resultar no mesmo efeito colateral.
No caso de GET, PUT, PATCH e DELETE, deve fazer
sempre a mesma coisa. O GET deve sempre retornar os mesmos dados (a não ser,
claro, que algo tenha sido alterado no sistema), PUT e PATCH devem sempre fazer
a mesma alteração se necessário, e DELETE deve excluir o item ou retornar um
erro.
Por exemplo. caso você execute um PUT várias vezes, ele não deve falhar na
segunda ou terceira requisição porque nada foi alterado, mas deve funcionar
sempre. Uma exceção para idempotente é o POST,
que nunca é idempotente. Toda vez que você fizer um POST em uma API, ela
sempre retornará um novo objeto/recurso.
Portanto, não importa se você fizer a mesma solicitação várias vezes, o
resultado deve ser sempre o mesmo, a menos, é claro, nos casos em que algum dado
foi alterado por outra solicitação entre as chamadas.
Cache
O cache é outro requisito quando pensamos na API RESTfull. Claro que nem todas
as APIs precisam ter cache, mas para escalar, o cache é algo que você deve
considerar.
“O armazenamento em cache seria inútil se não melhorasse significativamente o
desempenho. O objetivo do cache em HTTP/1.1 é eliminar a necessidade de enviar
solicitações em muitos casos e eliminar a necessidade de enviar respostas
completas em muitos outros casos.” (padrão HTTP)
O cache é uma técnica que armazena uma cópia de um determinado recurso e o
devolve quando solicitado. Quando um cache da web tem um recurso solicitado em
seu armazenamento, ele intercepta a solicitação e retorna sua cópia em vez de
fazer o download novamente do servidor de origem. Isso atinge vários objetivos:
alivia a carga do servidor que não precisa atender todos os clientes sozinho, e
melhora o desempenho por estar mais próximo do cliente, ou seja, leva menos
tempo para transmitir o recurso de volta. Para um site da Web, é um componente
importante na obtenção de alto desempenho. Por outro lado, ele deve ser
configurado adequadamente, pois nem todos os recursos permanecem idênticos para
sempre: é importante armazenar em cache um recurso apenas até que ele mude, não
mais.
É possível ter cache do lado do servidor (e isso é bom), o que significa que,
por exemplo, se dois ou mais clientes solicitarem o mesmo livro, você o
armazenou no servidor para devolvê-lo mais rapidamente. Mas o cache em uma API
REST significa usar HTTP para o mecanismo de cache. Por exemplo, quando você faz
uma solicitação HTTP para pedir algo e inclui a última versão que os dados foram
fornecidos, a resposta deve ser 304 — Não Modificado. Então neste caso o cliente
vai perguntar ao servidor se ele tem a versão mais recente sem que o servidor
tenha que achar e depois enviar de volta para você poder comparar.
O desempenho de sites e aplicativos da Web pode ser significativamente melhorado
com a reutilização de recursos obtidos anteriormente. Os caches da Web reduzem a
latência e o tráfego de rede e, portanto, diminuem o tempo necessário para
exibir uma representação de um recurso. Ao usar o cache HTTP, os sites da Web se
tornam mais responsivos.
Cabeçalho If-Match
O cabeçalho de solicitação HTTP "If-Match" é utilizado para realizar operações condicionais em recursos de um servidor. Ele é geralmente usado em conjunto com o método HTTP PUT ou PATCH para verificar se uma versão específica de um recurso está presente no servidor antes de fazer alterações nele.
O cabeçalho "If-Match" contém um valor que representa uma etag (tag de entidade) associada a uma versão específica do recurso. Uma etag é um identificador único que o servidor atribui a uma determinada versão de um recurso. Quando você envia uma solicitação PUT ou PATCH juntamente com o cabeçalho "If-Match", o servidor compara a etag fornecida com a etag atual do recurso. Se as etags corresponderem, significa que você possui a versão mais recente do recurso e a solicitação é processada. Caso contrário, o servidor pode responder com um código de status 412 (Pré-condição falhou), indicando que a etag fornecida não corresponde à versão atual do recurso e que você precisa atualizar sua cópia antes de prosseguir.
O cabeçalho "If-Match" também pode ser usado com o valor especial "*" para indicar que qualquer versão do recurso é aceitável. Isso pode ser usado, por exemplo, para solicitar a criação de um recurso somente se ele ainda não existir.
Tags de Entidade (ETags)
Uma boa maneira de lidar com esse cache é usando tags de
entidade (Etags). Ele suporta cache forte e semanal. O cache forte é
usado para oferecer suporte a itens que permanecerão por um longo período de
tempo, por exemplo, se você precisar armazenar algo em cache por três semanas. O
cache da semana é para coisas que terão um tempo de vida muito curto.
O cabeçalho de resposta HTTP ETag é um
identificador para uma versão específica de um recurso. Ele permite que os
caches sejam mais eficientes e economizem largura de banda, pois um servidor da
Web não precisa reenviar uma resposta completa se o conteúdo não tiver sido
alterado. Além disso, os etags ajudam a impedir que atualizações simultâneas de
um recurso sobrescrevam umas às outras ("colisões no ar").
Essas ETags serão retornadas na resposta com algum identificador exclusivo que
representa a versão do recurso no servidor e serão retornadas no cabeçalho. Por
exemplo:
Marca ET: "33a64df551425fcc55e4d42a148795d9f25f89d4"
No caso de precisar retornar um tipo de semana, você começa com
W/ e depois usa o mesmo formato em uma ETAG, dessa forma é possível
indicar ao desenvolvedor o quão forte é esse suporte de cache:
Marca ET: W/"33a64df551425fcc55e4d42a148795d9f25f89d4"
Esse identificador exclusivo será retornado no cabeçalho e também pode ser usado para fins de rastreamento.
Evitando colisões no ar
Usar ETag e If-Match pode ser útil para detectar
colisões de edição no ar. Por exemplo, quando algo é atualizado, um
identificador exclusivo será adicionado a um cabeçalho Etag na resposta:
Marca ET: "33a64df551425fcc55e4d42a148795d9f25f89d4"
Quando alguém atualizar, a solicitação conterá o cabeçalho
If-Match contendo os ETagvalues a serem
verificados:
Se corresponder: "33a64df551425fcc55e4d42a148795d9f25f89d4"
Se o identificador exclusivo não corresponder, isso significa que o recurso foi
editado no meio e um erro 412 — Falha na condição prévia será lançado.
Versionando da
API
O controle de versão da API é importante para evitar alterações de interrupção
nos clientes. Por exemplo, imagine que um ou mais clientes estão usando sua API,
e você fez algumas alterações na API que afetam a forma como os dados são
estruturados e, uma vez publicada essa nova alteração, não será possível para os
clientes usarem a API mais, a menos que eles também atualizem do lado deles.
Então, para evitar uma situação como essa, podemos trabalhar com versionamento.
Por exemplo, a primeira versão da API será v1.0 e a segunda será v2.0. Quando a
versão 2 for lançada, ainda será possível usar a versão 1 por um período de
tempo, e você poderá avisar seus clientes dizendo que em um determinado período
de tempo a versão 1 não estará mais disponível e eles precisam atualizar para a
versão 2.
Após esse período, você pode desativar a
versão 1 da API. Dessa forma, quando você atualizar sua API, mesmo que atualize
algo que possa causar uma mudança de quebra, isso não afetará diretamente quem
já está usando, e você dará um tempo aos seus clientes para que eles atualizem
seu aplicativo com a versão mais recente da sua API.
Isso também é útil em situações em que você tem muitos clientes e um deles
precisa de um recurso específico o mais rápido possível, mas esse recurso pode
causar algumas alterações de interrupção. Nesse caso, você pode criar uma nova
versão, e o cliente que precisa desse novo recurso já pode usar, e os outros
clientes terão um tempo para atualizar.
Mudanças importantes sempre devem resultar em uma mudança no número da versão
principal para uma API ou tipo de resposta de conteúdo. Mudanças importantes
incluem:
Se a API for usada apenas por sua própria equipe e seu próprio aplicativo, talvez criar versionamento para a API seja um exagero, mas nos casos em que a API está sendo usada por clientes internos ou externos, o versionamento da API é muito importante.
Estratégias para versionar a API
O REST não fornece diretrizes específicas de versão, mas algumas das estratégias
que podem ser usadas são:
- Controle de versão usando a versão da API no URI
- Controle de versão usando uma Query String
- Controle de versão com cabeçalho de solicitação personalizado
- Versionamento com Aceitar Cabeçalho
- Controle de versão com tipo de conteúdo
Protegendo a API
Você deve sempre considerar proteger sua API nos casos em que:
- A API fará uso de dados privados ou personalizados
- A API enviará dados confidenciais para acessar a rede
- A API usará qualquer tipo de credencial
- A API tentará proteger contra o uso excessivo de seus servidores
Autenticação vs. Autorização
Em termos simples, Autenticação é “quem você é”. Autenticação é sobre as
informações usadas para determinar sua identidade, isso pode incluir credenciais
como nome de usuário e senha ou reivindicações, e o servidor pode usar essas
informações para identificá-lo e garantir que você seja exatamente quem diz ser.
Autorização é “o que você pode fazer”, com base nas informações de autenticação,
com base na própria identidade. A autorização está relacionada a regras sobre
direitos, papéis, permissões.
Tipos de autenticação para APIs
As formas mais comuns de proteger uma API são:
Cookies — Usar cookies é fácil e comum, mas
não é tão seguro. Dependendo do nível de segurança que você precisa, os cookies
podem ser uma boa opção, mas se você precisar de algo mais seguro, use outra
abordagem. Um cookie HTTP (cookie da web, cookie do navegador) é um pequeno
pedaço de dados que um servidor envia ao navegador da web do usuário. O
navegador pode armazená-lo e enviá-lo de volta com solicitações posteriores para
o mesmo servidor. Normalmente, é usado para saber se duas solicitações vieram do
mesmo navegador – mantendo um usuário conectado, por exemplo. Ele lembra
informações com estado para o protocolo HTTP sem estado.
Basic Auth — Isso também é muito usado e é
fácil de implementar. Basic Auth permite passar a informação na query string ou
nos cabeçalhos, com as credenciais a validar no servidor. Isso também não é tão
seguro porque pode vazar o nome de usuário e a senha dos usuários. As
credenciais serão enviadas a cada solicitação e alguém poderá interceptá-las e
obtê-las.
Autenticação Baseada em Token — Este é o
mais comumente usado e tem uma mistura de segurança e simplicidade. Existe um
padrão para esses tokens e geralmente há um middleware que dará suporte à
criação e validação desses tokens na maioria das plataformas.
OAuth — OAuth tem alguns padrões e é usado
para permitir que terceiros confiáveis identifiquem usuários. Dessa forma, o
aplicativo que está usando OAuth nunca obtém a credencial. Assim, por exemplo,
se você deseja fazer login, pode usar sua conta do Gmail ou da Microsoft, em vez
de informar o nome de usuário e a senha.
Autenticação via token
Existem diversos tipos de Token, um dos mais comuns e mais utilizados é o Token
JWT. Com essa abordagem, o token será enviado no cabeçalho da requisição, da
seguinte forma:
bearer
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36
POk6yJV_adQssw5c
Funciona assim:
- O cliente enviará uma solicitação ao servidor com suas credenciais (pode ser por exemplo o nome de usuário e a senha), o servidor validará essa autenticação e retornará um token, que é uma série de caracteres.
- O cliente não precisa decodificar este token, apenas o utilizará para enviar as requisições. Em uma aplicação SPA por exemplo, o navegador vai armazenar esse token (em uma aplicação mobile você pode armazenar isso no cache do app) e toda vez que o cliente solicitar algo, o token será enviado no cabeçalho da requisição.
- O servidor então lerá este token e validará se o usuário tem autorização para executar aquela ação e retornará uma resposta;
Token JWT
JSON Web Token (JWT) é um padrão aberto (RFC 7519) que define uma maneira
compacta e independente de transmitir informações com segurança entre as partes
como um objeto JSON.
Essas informações podem ser verificadas e confiáveis porque são assinadas digitalmente. Os JWTs podem ser assinados usando um segredo (com o algoritmo HMAC) ou um par de chaves pública/privada usando RSA ou ECDSA.
Um token JWT consiste em três partes:
Ao contrário dos cookies, que são passados automaticamente para o servidor, o token JWT precisa ser explicitamente passado para o servidor pelo cliente.
Então, um fluxo simplificado de operações seria o seguinte:
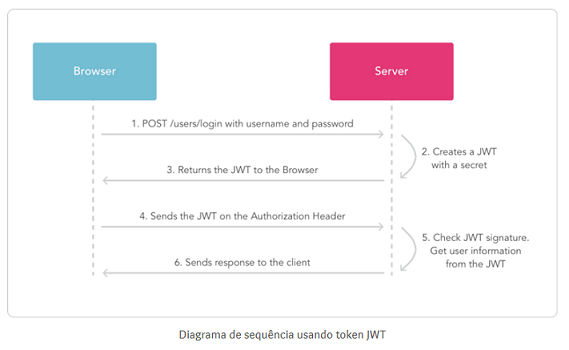
1- O cliente envia credenciais de segurança, como nome
de usuário e senha, para o servidor para validação;
2- O servidor valida o nome de usuário e a senha;
3- Se as credenciais forem válidas, o servidor gera e emite um token JWT para o
cliente;
4- O cliente recebe o token e o armazena em algum lugar;
5- Ao solicitar qualquer recurso ou ação do servidor, o cliente adiciona o token
JWT emitido anteriormente no cabeçalho Authorization da requisição;
6- O servidor lê o cabeçalho de autorização para recuperar o token JWT;
7- Se o token for válido, o servidor executará a ação solicitada pelo cliente;
Então, basta pensar no token JWT como um ticket. Se a requisição recebida
tiver um ticket válido, ela poderá acessar um recurso.
Conclusão
APIs REST são muito utilizadas em muitas aplicações hoje em dia, são leves,
rápidas e funcionam muito bem. Seguir os princípios que foram citados neste
artigo permite que você tenha um bom design em suas APIs, mas não fique tão
restrito quanto a isso, sempre leve em consideração o que sua aplicação
realmente precisa e faça uso dos princípios que serão bons para seu aplicativo.
E estamos conversados.
![]()
"Em tudo somos atribulados, mas não angustiados; perplexos, mas não desanimados.
Perseguidos, mas não desamparados; abatidos, mas não destruídos;
Trazendo
sempre por toda a parte a mortificação do Senhor Jesus no
corpo, para que a
vida de Jesus se manifeste também no nosso corpo;"
2 Coríntios 4:8-10

Referências: