 |
Neste artigo veremos como implementar o padrão Repository fazendo o cache e usar o HangFire de forma a obter um melhor desempenho em uma aplicação ASP .NET Core usando a arquitetura cebola. |
Este artigo e o projeto nele apresentado foram baseados em outros artigos e
projetos existentes a partir dos quais as ideias e parte do código foi
utilizado, com foco no artigo -
Repository Pattern with Caching and Hangfire in ASP.NET Core.


Apresentando o cenário
O objetivo é criar uma API REST usando o template da ASP.NET Core Web App que gerencia informações de alunos realizando operações CRUD. Para aumentar o desempenho da API vamos incluir o uso de um cache genérico no projeto de permitindo o seu uso com o Redis ou outras tecnologias. Além disso vamos integrar o cache ao Hangfire para que ele possa ser executado em segundo plano.
Então, a ideia é o projeto são simples e em linhas gerais atua da seguinte forma:
Vamos implementar o padrão repositório tradicional junto com o DBContext do Entity Framework Core. Toda vez que um usuário solicitar dados do cliente, precisamos verificar se eles já existem no cache, caso contrário, vamos recuperá-los do banco de dados e armazená-los em cache, e, sempre que alguém excluir ou modificar um registro, os dados armazenados em cache devem ser invalidados e armazenados em cache novamente. O armazenamento em cache novamente pode levar algum tempo. Assim, definimos esse processo de armazenamento em cache como um trabalho em segundo plano usando o Hangfire.
recursos usados:
-
Visual Studio 2022
-
.NET 6
-
EF Core
-
Onion Architecture
-
Cache
-
Hangfire
-
Bogus
Arquitetura Cebola
Na criação do projeto vamos usar a arquitetura Cebola ou Onion que usa o conceito de camadas, mas que é diferente das camadas da arquitetura de três e n-camadas.
A seguir temos uma figura que mostra a disposição das camadas na Onion Architecture :
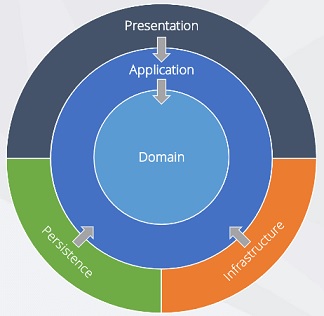
A regra de ouro da arquitetura é: "Nada em um círculo interno pode saber absolutamente nada sobre algo em um círculo externo. Isso inclui métodos, classes, variáveis ou qualquer outra entidade de software nomeada." Robert C. Martin
Obs: Essa regra também existe em outras arquiteturas semelhantes,
como Arquitetura Limpa (Clean Architecture).
Esta regra depende da injeção de dependência para fazer sua abstração das
camadas, para que você possa isolar suas regras de negócios de seu código de
infraestrutura, como repositórios e views.
- A Camada de Domínio ou Core (Domain Layer)
- A Camada de Aplicação (Application Layer)
- A Camada de infraestrutura (Infrastructure Layer)
Vamos tomar como base as diretrizes desta arquitetura fazendo os ajustes para o nosso cenário.
Criando a solução e os projetos
Vamos iniciar criando uma solução em branco usando o template Blank Solution do VS 2022 com o nome AlunosWeb.
A seguir vamos incluir 4 projetos nesta solução :
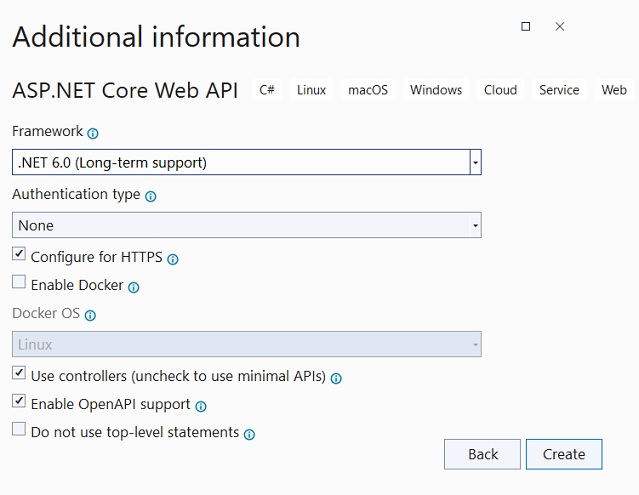
1- Um projeto ASP .NET Core Web Api chamado
AlunosWeb.Api. As configurações usadas neste projeto são exibidas a
seguir:
2- Um projeto do tipo Class Library chamado
AlunosWeb.Core;
3- Um projeto do tipo Class Library chamado
AlunosWeb.Infra.Data;
4- Um projeto do tipo Class Library chamado AlunosWeb.Infra.IoC
A estrutura da solução exibida na janela Solution Explorer é exibida abaixo:
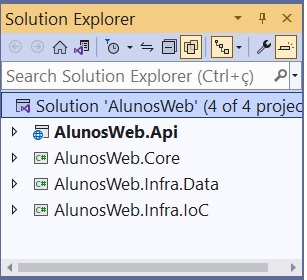
Observe que eu dividi o projeto Infrastructure em dois projetos : Infra.Data e Infra.IoC
Definindo as referências entre os projetos
Agora vamos definir as referências entre os projetos e para isso devemos respeitar a regra de ouro arquitetura Onion.
Assim podemos definir as seguintes dependências entre os projetos:
- AlunosWeb.Core - Não possui nenhuma dependência de outro projeto;
- AlunosWeb.Api - Possui dependência do projeto AlunosWeb.Infra.IoC;
- AlunosWeb.Infra.Data - Possui dependência do projeto AlunosWeb.Core;
- AlunosWeb.Infra.IoC - Possui dependências do projeto Alunos.Web.Core e Infra.Data;
Para incluir as dependencias selecione o projeto, a seguir clique com o botão direito do mouse e selecione a opção Add-> Project Reference;
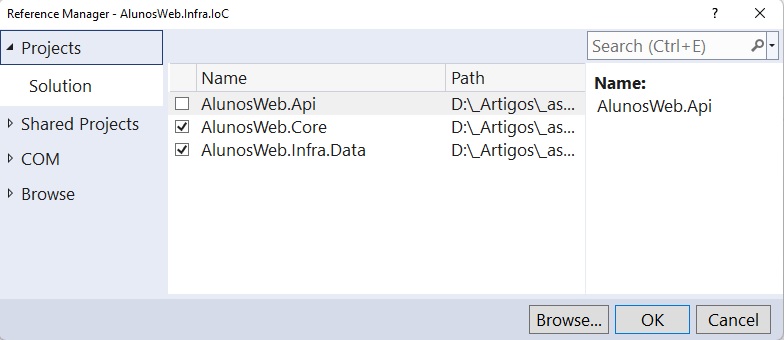
Na janela - Reference Manager - marque os projetos e clique em OK.
Criando as pastas e Incluindo os pacotes Nugets nos projetos
Agora em cada projeto iremos criar as pastas necessárias e incluir os pacotes Nugets que iremos usar.
Vamos iniciar como o projeto Core que não possui nenhuma dependência criando as pastas :
- Entities
- Enumerations
- Interfaces
Na pasta Entities vamos criar a entidade Aluno que representa o nosso domínio. Aqui para simplificar vou criar uma classe POCO :
public class Aluno
{
public int Id { get; set; }
public string Nome { get; set; } = string.Empty;
public string Email { get; set; } = string.Empty;
public DateTime Nascimento { get; set; }
public string? Sexo { get; set; }
}
|
A seguir vamos incluir os pacotes nugets no projeto Infra.Data onde vamos definir o arquivo de contexto, as implementações dos repositórios e serviços relacionados com a infraestrutura.
Aqui vamos incluir os pacotes do Entity Framework Core , do HangFire e do Bogus. Para isso podemos usar os seguintes comandos:
- install-package <nome>
- dotnet add package <nome>
A seguir inclua neste projeto os seguintes pacotes:
- Microsoft.EntityFrameworkCore.SqlServer
- Microsoft.EntityFrameworkCore.Design
- HangFire
- Bogus
A seguir vamos criar as seguintes pastas neste projeto:
- Context
- Repositories
- Services
A pasta Context vai conter o arquivo de contexto ApplicationDbContext que vai herdar de DbConext e vai conter o mapeamento ORM usando o EF Core na abordagem Code-First.
Crie nesta pasta o arquivo ApplicationDbContext com o código abaixo:
public class ApplicationDbContext : DbContext
{
public ApplicationDbContext(DbContextOptions<ApplicationDbContext> options)
: base(options)
{
ChangeTracker.QueryTrackingBehavior = QueryTrackingBehavior.NoTracking;
}
public DbSet<Aluno>? Alunos { get; set; }
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
var ids = 1;
var stock = new Faker<Aluno>()
.RuleFor(c => c.Id, f => ids++)
.RuleFor(c => c.Nome, f => f.Name.FullName(Bogus.DataSets.Name.Gender.Female))
.RuleFor(c => c.Email, f => f.Internet.Email(f.Person.FirstName).ToLower())
.RuleFor(c => c.Nascimento, f => f.Date.Recent(100))
.RuleFor(c => c.Sexo, f => f.PickRandom(new string[] { "masculino", "feminino" }));
// gerar 300 items
modelBuilder
.Entity<Aluno>()
.HasData(stock.GenerateBetween(300, 300));
}
}
|
Neste código estamos desabilitando o rastreamento do EF Core para as consultas de forma a não afetar o tempo de execução das consultas quando formos obter dados do banco de dados.
O comportamento de rastreamento controla se o Entity Framework Core manterá informações sobre uma instância de entidade em seu rastreador de alterações. Se uma entidade for rastreada, quaisquer alterações detectadas na entidade persistirão no banco de dados durante SaveChanges(). O EF Core também corrigirá as propriedades de navegação entre as entidades em um resultado de consulta de rastreamento e as entidades que estão no rastreador de alterações.
Nota: Se
adicionarmos entidades ao contexto elas serão rastreadas e serão incluidas no
ChangeTracker.
A seguir mapeamentos a entidade Aluno para a tabela Alunos
e no método OnModelCreating estamos usando os
recursos do Bogus para gerar 300 dados fake em
nossa tabela Alunos.
Para saber como usar o Bogus veja o meu artigo: C# - Gerando Dados Fake com Bogus
No projeto Infra.IoC vamos criar a classe DependencyInjection e definir o método de extensão AddInfrastructureApi que vai atuar em ServiceCollection e onde iremos registrar os serviços no container DI.
Vamos criar aproveitar e registrar o serviço do contexto do EF Core representando por ApplicationDbContext :
public static class DependencyInjection
{
public static IServiceCollection AddInfrastructureApi(this IServiceCollection services,
IConfiguration configuration)
{
services.AddDbContext<ApplicationDbContext>(options =>
options.UseSqlServer(configuration.GetConnectionString("DefaultConnection"
), b => b.MigrationsAssembly(typeof(ApplicationDbContext).Assembly.FullName)));
return services;
}
}
|
No projeto Api vamos definir a chamada ao método de extensão AddInfrastructure para registrar o contexto do DF Core:
var builder = WebApplication.CreateBuilder(args);
// Add services to the container.
builder.Services.AddControllers();
builder.Services.AddEndpointsApiExplorer();
builder.Services.AddSwaggerGen();
builder.Services.AddInfrastructureApi(builder.Configuration);
var app = builder.Build();
app.UseSwagger();
app.UseSwaggerUI();
app.UseHttpsRedirection();
app.UseAuthorization();
app.MapControllers();
app.Run();
|
E no arquivo appsettings.json vamos definir a string de conexão com o SQL Server Local:
|
"ConnectionStrings":
{ "DefaultConnection": "Data Source=<Sua_Instancia>;Initial Catalog=AlunosWebDB;Integrated Security=True" }, |
Aqui definimos o nome do banco de dados que será criado como AlunosWebDB.
Agora vamos aplicar o migration no projeto para gerar o banco de dados e a tabela Alunos contendo os 300 registros de testes.
Para isso vamos usar a ferramenta EF Core Tools. Para instalar e/ou atualizar a ferramenta podemos usar os seguintes comandos:
-
Instala : dotnet tool install --global dotnet-ef -
Atualiza : dotnet tool update --global dotnet-ef
Com a ferramenta instala para criar a migração abra a janela Package Manager Console e digite o comando:
dotnet ef migrations add Inicial --project AlunosWeb.Infra.Data -s AlunosWeb.Api -c ApplicationDbContext --verbose
A seguir para aplicar a migração e criar o banco e a tabela com dados digite o comando:
dotnet ef database update Inicial --project AlunosWeb.Infra.Data -s AlunosWeb.Api -c ApplicationDbContext
Ao final podemos consultar o SQL Server Management Studio e verificar o conteúdo da tabela Alunos criada com os 300 registros:
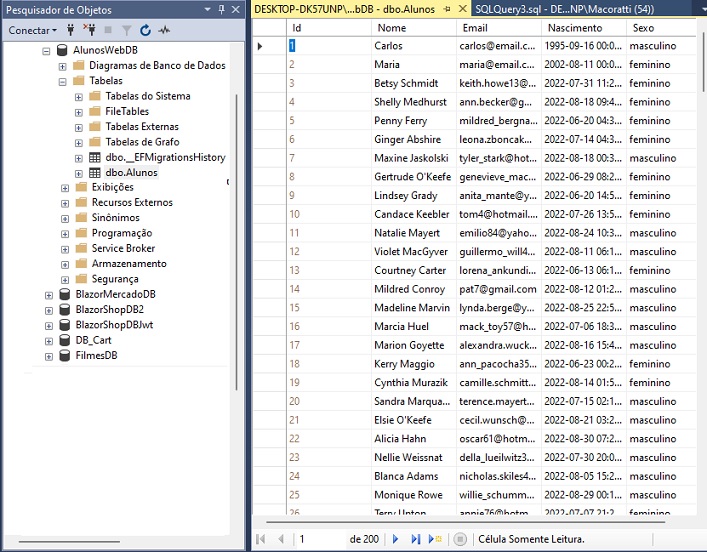
Graças ao Bogus temos os dados para estes incluídos na tabela Alunos com pouco esforço.
Adicionando o serviço de Cache
O cache é o
coração do nosso conceito. Com o cache, garantimos que os usuários podem
solicitar dados de nossa API sem esperar muito tempo. Assim, quando o primeiro
usuário solicita todos os dados os alunos, ele vai para o banco de dados, busca
os registros e também armazena esses dados em cache na memória do aplicativo ou
em qualquer serviço de cache externo como o Redis.
Agora, quando o segundo usuário solicitar os mesmos dados, não faria sentido
buscar no banco de dados, pois pode ser um pouco demorado; e como já temos os
dados armazenados em cache, por que não devolvê-los ? Isso economiza muito tempo
para as solicitações consequentes.
A primeira pergunta é quais são os dados do alunos que foram alterados durante o
tempo entre a 1ª solicitação e a 2ª e a 3ª solicitação ?
Se ainda servirmos os dados em cache, poderemos estar informando dados inválidos que foram alterados.
Portanto, a
solução é sempre que houver uma modificação nos dados dos alunos, teremos que
remover o cache e recuperá-lo de alguma forma usando os recursos do
Hangfire.
Vamos começar a construir um serviço de cache genérico. A principal intenção é
testar no futuro nossa solução para que possamos integrar várias técnicas de
Cache conforme e quando exigido pela aplicação.
Na
próxima parte
do artigo vamos iniciar com o cache.
![]()
"Não será assim entre vós; mas todo aquele que quiser entre vós fazer-se grande
seja vosso serviçal;
E, qualquer que entre vós quiser ser o primeiro, seja
vosso servo;"
Mateus
20:26,27

Referências:
-
ASP.NET 2.0 - Gerando relatórios com o ReportViewer
-
ASP .NET MVC 5 - Relatórios PDF com o plugin Rotativa
-
Relatórios e Crystal Reports
-
VB.NET - Criando um relatório com PrintDocument
-
Gerando relatórios via Crystal Reports com DataSets
-
C# - Crystal Reports - Usando múltiplas tabelas
-
Gerando relatórios a partir de arquivos XML
-
Crystal Reports - Instalando no VS 2019 Community
-
Gerando Relatório em uma aplicação ASP .NET - YouTube
-
ASP .NET Core MVC - Gerando arquivos PDF
-
C# - O Padrão Singleton (revisitado)
-
C# - Padrão Singleton
-
C# - Conceitos básicos - Classes Estáticas
-
How to Dynamically Register Entities in DbContext ...
-
.NET - Onion Architecture : Criando um projeto fácil de manter
-
A arquitetura em cebola (Onion Architecture)