![]() Docker - Persistência com SQL Server, PostgreSQL, MySQL, MongoDB
Docker - Persistência com SQL Server, PostgreSQL, MySQL, MongoDB
 |
Neste artigo veremos como containerizar e acessar os principais bancos de dados do mercado usando o Docker. |
O Docker não foi criado com persistência em mente, e um dos recursos mais atraentes dos contêineres é sua capacidade de ser iniciado e encerrado à vontade, assim, os dados no contêiner são transitórios e são apagados com o contêiner.


Por este motivo devemos ter cuidado ao usar serviços de banco de dados em containers em ambiente de PRODUÇÃO.
Se seu banco de dados
não for um serviço crítico, talvez você possa testá-lo no Docker; caso
contrário, você está entrando em uma zona perigosa que poderá te trazer muitos
problemas.
Se você estiver implantando em uma nuvem, a melhor opção é usar serviços de
banco de dados em nuvem (AWS Relational Database Service (RDS), Azure
Databases, Google Cloud Databases, Managed Databases on Digital Ocean ou um
serviço de banco de dados hospedado equivalente do seu provedor de nuvem).
Agora vejamos outro cenário onde temos alguns mecanismos de banco de dados diferentes em nossos projetos, ou temos versões diferentes de qualquer (ou todos) deles, ou onde temos equipes com outros sistemas operacionais ou com uma configuração diferente, ou você precisa preparar o ambiente para um novo membro da equipe.
Neste casos, para não
sobrecarregar nossa máquina de trabalho com diferentes instalações e versões
podemos fazer isso em um só lugar facilmente usando o Docker por meio dos
comandos docker CLI ou de um docker-compose, e, podemos fazer isso
adicionando e removendo recursos sem afetar o resto do sistema.
Como mencionado anteriormente, os contêineres não existem com persistência em
mente, mas geralmente queremos ter dados mesmo se reiniciarmos nosso mecanismo
de contêiner ou máquina de trabalho.
Felizmente, existem algumas maneiras de preservar os dados em um contâiner e o
Docker trata com a persistência em geral de duas formas:
Essas duas abordagens permitem que você monte uma localização na máquina host para armazenar os dados do container. Isso fornece armazenamento para os dados mesmo se o contêiner for encerrado e não há necessidade de se preocupar com a perda de dados.
Vejamos como funciona a primeira opção.
1- Usando Bind mounts
Na abordagem bind mounts será montado um arquivo ou diretório para o contêiner a partir da máquina host e, em seguida, ele poderá ser referenciado por meio de seu caminho absoluto.
Ele depende do sistema de arquivos da máquina host ter uma estrutura de diretório específica. Caso contrário, é necessário criar explicitamente um caminho para o arquivo ou pasta para colocar o armazenamento. Além disso, esta abordagem nos dá acesso a arquivos confidenciais e podemos alterar o sistema de arquivos do host por meio de processos executados em um contêiner, o que é considerado uma implicação de segurança.
Podemos usar os sinalizadores --mount e -v para usar montagens de ligação em um contêiner.
A diferença mais notável entre as duas opções é que --mount é mais explícito e detalhado, enquanto -v é mais um atalho para --mount. Ele combina todas as opções --mount em um único campo.
Vejamos um exemplo prático usando o banco de dados PostgreSQL:
docker run --rm --name pgdb -e POSTGRES_PASSWORD=numsey#2022 --mount type=bind,source="$(pwd)",target=/var/lib/postgresql/data -p 2000:5432 -d postgres
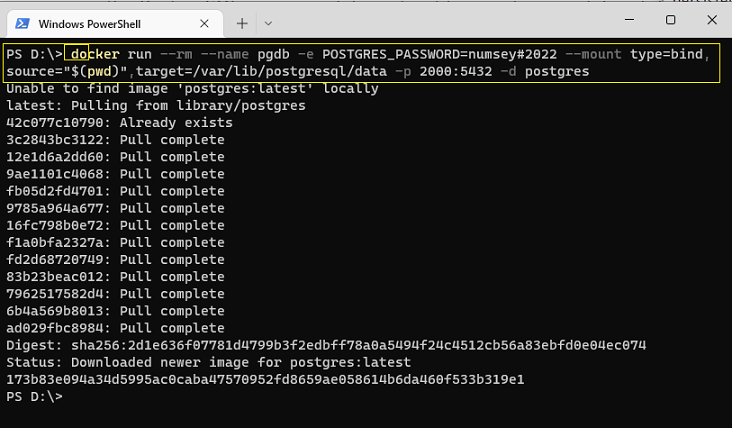
Nosso contêiner PostgreSQL está em execução e agora pode ser acessado a partir da ferramenta de banco de dados apropriada (como o DBeaver Community, pgAdmin, etc).
Estamos usando a porta 2000 e a senha numsey#2022 para conectar à nossa instância de banco de dados, conforme definimos anteriormente no comando da CLI do Docker.

2- Usando Volumes do Docker
Na abordagem onde
usamos os volumes temos que o Docker gerencia totalmente os volumes do docker;
portanto, eles não são afetados por nossa estrutura de diretórios ou pelo
sistema operacional da máquina host. Quando utilizamos um volume, o Docker cria
um novo diretório no diretório de armazenamento da máquina host e o Docker
manipula seu conteúdo. Para volumes do Docker, o armazenamento não está
associado ao ciclo de vida do contêiner e reside fora do contêiner.
Algumas das vantagens:
- Elimina os contêineres conforme necessário e ainda retém
seus dados;
- Anexa os volumes a vários contêineres em execução ao mesmo tempo;
- Reutiliza o armazenamento em vários contêineres (por exemplo, um contêiner
grava no armazenamento e outro lê no armazenamento)
- Os volumes não aumentam o tamanho dos contêineres do Docker que os utilizam;
- Podemos usar a CLI do Docker para gerenciar seus volumes (por exemplo,
recuperar uma lista de volumes ou excluir volumes não utilizados).
a- Exemplo usando o SQL Server:
docker run --rm --name macmssql -e "ACCEPT_EULA=Y" -e "SA_PASSWORD=numsey#2022" -e "MSSQL_PID=Express" --mount type=volume,source=custommssql,target=/var/opt/mssql -p 7000:1433 -d mcr.microsoft.com/mssql/server:2019-latest
Podemos fazer a conexão com o banco no container através do SQL Server Management Studio:
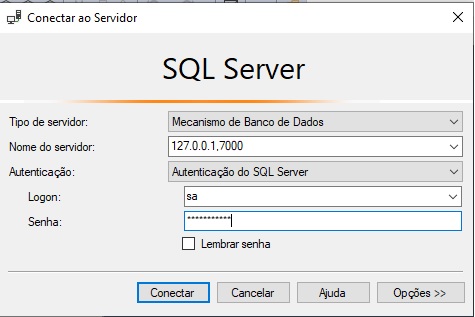
Informamos :
b- Exemplo usando o PostgreSQL:
docker run --rm --name macpostgresql -e POSTGRES_PASSWORD=numsey#2022 --mount type=volume,source=custompostgres,target=/var/lib/postgresql/data -p 7001:5432 -d postgres:latest
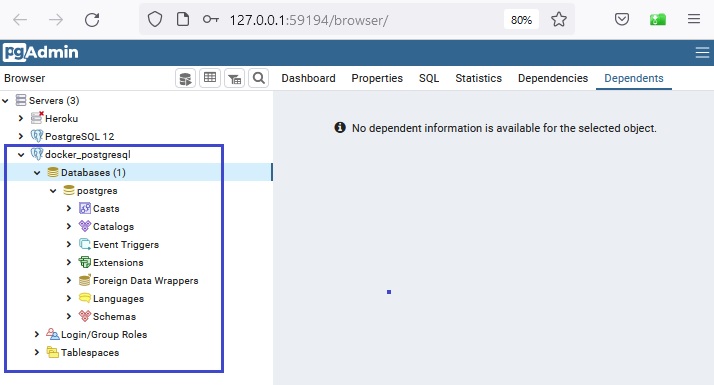
Vamos acessar o PostgreSQL no container usando o PgAdmin e criando a conexão:

Criamos uma nova conexão chamada docker_postgresql onde informamos:
c- Exemplo usando o MySQL:
docker run --rm --name macmysql -e MYSQL_ROOT_PASSWORD=numsey#2022 --mount type=volume,source=custommysql,target=/var/lib/mysql -p 7003:3306 -d mysql:latest
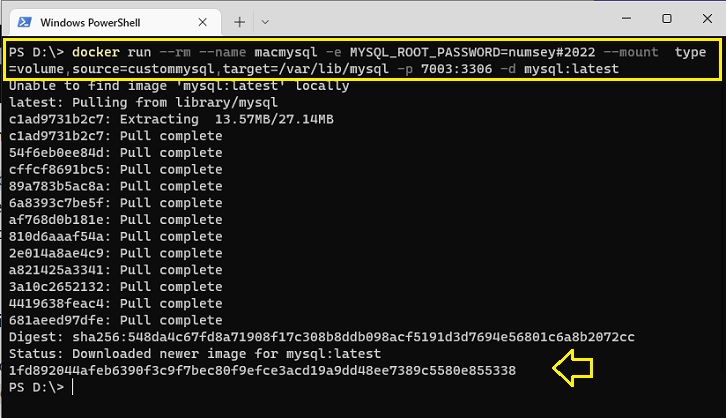
Podemos acessar o MySQL no container usando o MySq lWorkbench e criando uma conexão:
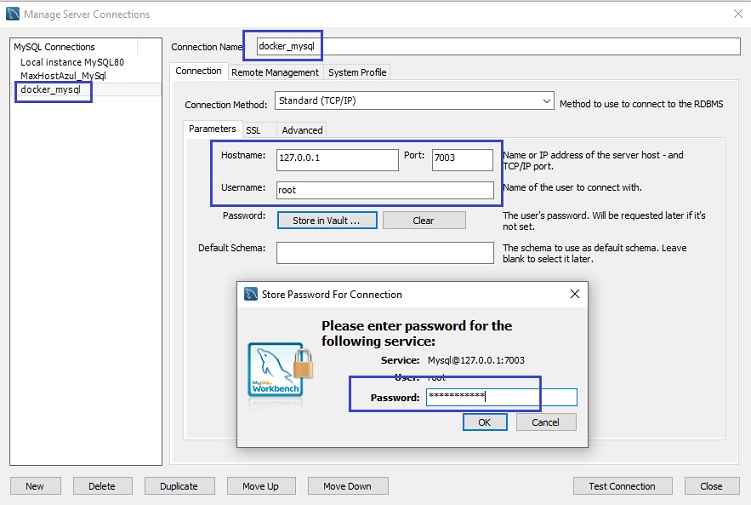
Para a conexão informamos:
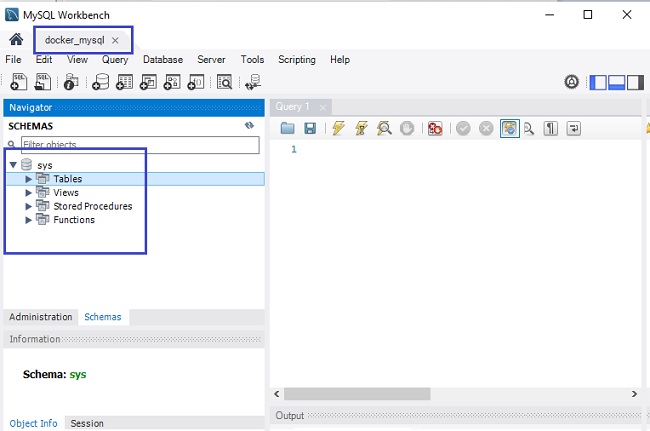
d- Exemplo usando o MongoDB:
docker run --rm --name macmongo -e MONGO_INITDB_ROOT_USERNAME=macora -e MONGO_INITDB_ROOT_PASSWORD=numsey@2022 --mount type=volume,source=custommongo,target=/data/db -p 7004:27017 -d mongo:latest

A imagem usada também vai criar um volume para /data/configdb, portanto, você verá um volume de ID hexadecimal adicional em seus volumes do Docker.
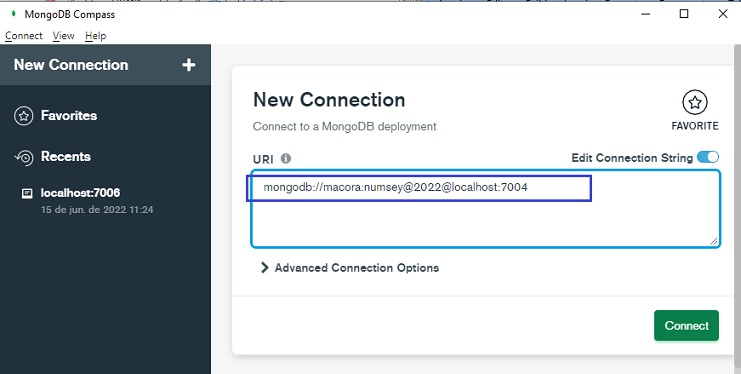
Para conectar usamos a seguinte informação: URI - mongodb://macora:numsey@2022@localhost:7004
Usando o MongoDB Compass informamos:
Podemos conferir o nosso ambiente usando o dashboard do Docker Desktop for Windows onde temos:
1- As imagens usadas para o SQL Server, Mongo, MySQL e PostgreSQL
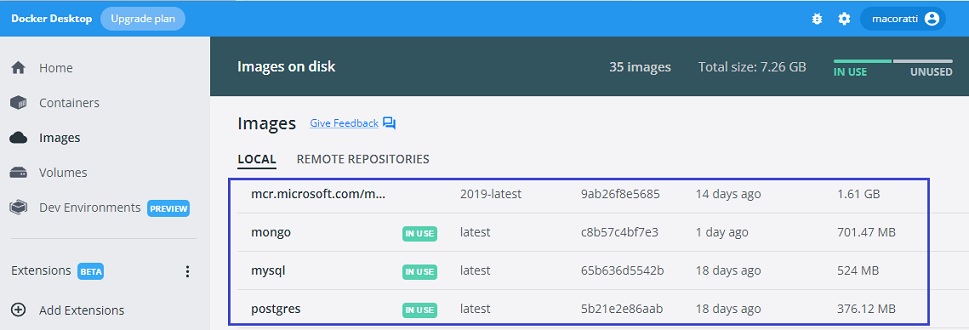
2- Os respectivos containeres criados em execução

3- Os volumes que foram montados para os respectivos banco de dados no host:
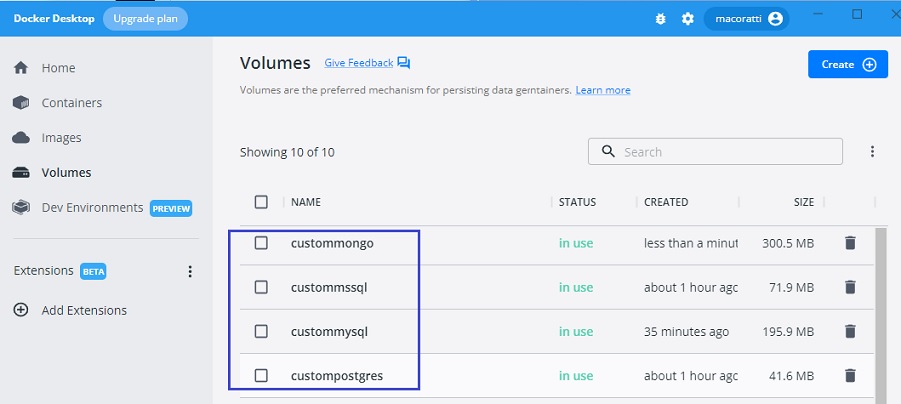
Visualizando os volumes usando o comando : docker volume ls

Ao invés de usar a linha de comando com a CLI do Docker também podemos usar um arquivo docker-compose para cada um dos banco de dados e assim definir a conexão.
Exemplo de docker-compose para o SQL Server:
|
version: '3.4'
services: volumes: |
Isso permite gerenciar de forma mais adequada cada conexão com cada banco de dados no seu ambiente.
De acordo com a documentação do Docker, o uso de volumes é a abordagem mais direta para iniciar a persistência de dados em seu contêiner do Docker. Em geral, a abordagem - bind mounts ou montagens de ligação - têm restrições adicionais de uso e deve ser evitada.
Dessa forma temos em nosso ambiente a execução e a persistência sendo usada para 4 banco de dados rodando em 4 containeres independentes e após a execução cada container será destruído sendo os dados persistidos nos volumes criados para cada banco.
Com isso nosso ambiente esta livre e conseguimos configurar o uso de cada banco para a nossa necessidade graças ao Docker
E estamos
conversados ![]()
'Como, pois,
invocarão aquele em quem não creram? e como crerão naquele de quem não
ouviram? e como ouvirão, se não há quem pregue?'
Romanos 10:14

Referências:
C# 9.0 - Instruções de nível superior
ASP.NET Core Web API - Apresentando API Analyzers
ASP.NET Core - Usando o token JWT com o Swagger
Docker - Uma introdução básica - Macoratti.net
Docker - Trabalhando com contêineres - Macoratti.net
Docker - Criando um Contâiner para .NET Core (3.0)
Docker - MiniCurso Básico - Macoratti.net
Motivos para usar Docker com .NET Core