![]() .NET -
Onion Architecture : Criando um projeto fácil de manter
.NET -
Onion Architecture : Criando um projeto fácil de manter
 |
Neste artigo vou apresentar os principais conceitos da Onion Architecture e como podemos usá-los para criar um projeto de software que seja fácil de manter, testar e estender. |
O termo
Onion Architecture foi cunhado por
Jeffrey Palermo em 2008. Essa arquitetura
fornece uma alternativa robusta para criar aplicativos para uma melhor
testabilidade, manutenção e confiabilidade.

Criando um projeto de software sustentável
No desenvolvimento de
software, uma das coisas mais importantes a se ter em mente é que o software
deve estar sempre em evolução, recebendo novas funcionalidades, melhorias
e correções de bugs.
Portanto, podemos ver que é importante construir um software que seja
sustentável, ou seja, um software que possa ser mantido hoje e no futuro
independente de quem for trabalhar com ele.
Mas, o que é software sustentável ?
Um software sustentável é um software que qualquer desenvolvedor deve ser capaz de fazer melhorias e
correções sem se preocupar em quebrar o código. Qualquer desenvolvedor,
familiarizado com o domínio, deve ser capaz de entender o código e saber
facilmente onde alterar as coisas.
Dessa forma modificar a camada de apresentação não deve quebrar nenhuma lógica de domínio,
modificar a modelagem de banco de dados não deve afetar as regras de negócios do
projeto. Além disso, a lógica do domínio deve ser capaz de ser testada facilmente.
Com essa premissa, devemos começar a pensar em separar diferentes interesses em diferentes
unidades de código usando uma arquitetura que nos auxilie neste objetivo.
O que é a Onion Architecture ?
A Onion Architecture é um padrão de arquitetura que propõe que o software deve ser feito em camadas, cada camada com sua própria preocupação ou responsabilidade, e, foi proposta por Jeffrey Pallermo em seu site.
Abaixo temos uma figura que mostra a disposição das camadas na Onion Architecture :
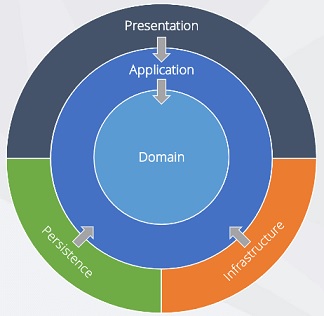
A regra de ouro da arquitetura é: "Nada em um círculo interno pode
saber absolutamente nada sobre algo em um círculo externo. Isso inclui métodos,
classes, variáveis ou qualquer outra entidade de software nomeada." Robert
C. Martin
Obs:Essa regra também
existe em outras arquiteturas semelhantes, como
Arquitetura Limpa (Clean Architecture).
Esta regra depende da injeção de dependência para fazer sua abstração das camadas,
para que você possa isolar suas regras de negócios de seu código de
infraestrutura, como repositórios e views.
A seguir vamos descrever essas camadas e os recursos que cada uma utiliza.
A camada de Domínio (Domain Layer)
A Camada de Domínio é a camada mais interna da arquitetura.
Os modelos de domínio e os modelos de serviços estarão dentro desta camada, contendo todas as regras de negócio do software que devem ser puramente lógicas, não realizando nenhuma operação IO. Como essa camada é puramente lógica, deve ser muito fácil testá-la, pois você não precisa se preocupar em simular operações de IO.
Ao isolar sua lógica de domínio, o domínio se torna fácil de testar e manter.
Essa camada também não pode saber sobre o que for declarado nas camadas Application ou Infrastructure.
Modelos de domínio
Os Modelos de Domínio são o núcleo da Camada de Domínio. Eles representam os modelos de negócios, contendo as regras de negócios de seu domínio.
Serviços de domínio
Existem alguns casos em que é difícil ajustar um comportamento em um
único modelo de domínio. Imagine que você está modelando um sistema
bancário, onde tem o modelo de domínio Conta. Em seguida,
você precisa implementar o recurso de transferência, que envolve
duas contas.
Não está tão claro se esse comportamento deve ser implementado pelo
modelo de Conta, então você pode escolher implementá-lo em um
serviço de domínio.
Assim, um serviço de domínio contém um comportamento que não está vinculado a um modelo de domínio específico. Pode ser basicamente uma função, em vez de um método. Observe que, você deve sempre tentar implementar comportamentos em Modelos de Domínio para evitar cair na armadilha do Modelo de Domínio Anêmico.
Camada de aplicação (Application Layer)
A
Camada de Aplicação é a segunda camada mais interna da
arquitetura.
Esta camada é responsável por preparar o ambiente para seus modelos,
para que possam executar suas regras de negócio.
Esta camada implementa regras de aplicativo (às vezes chamadas de
casos de uso) em vez de regras de negócios. As regras de
aplicativos são diferentes das regras de negócios. As primeiras são
regras que são executadas para implementar um caso de uso de seu
aplicativo. Estas últimas são regras que pertencem ao próprio
negócio.
Exemplo de regra de aplicativo:
Exemplo de regra de negócios:
Portanto, com base
nos exemplos, se o sistema não tivesse ainda sido criado, as regras
de negócios ainda seriam aplicadas. As regras do aplicativo não, pois dependem do
aplicativo.
Observe que a própria camada de aplicativo não implementa nenhuma operação IO. A
única camada que implementa IO é a camada de infraestrutura.
A camada de aplicativo apenas chama métodos de objetos que implementam as
interfaces que ela espera, e esses objetos (da camada de infraestrutura)
podem fazer algum operação IO.
Serviços
Um serviço de aplicativo é um pedaço de código que implementa um caso de uso.
Ele pode receber objetos que implementam algumas interfaces conhecidas (injeção
de dependência) e tem permissão para importar entidades da Camada de
Domínio.
Interfaces
Se a camada de aplicativo deve coordenar operações que envolvem operações IO,
como carregar dados de um repositório ou enviar um e-mail, ela deve declarar
algumas interfaces com os métodos que deseja usar.
Esta camada não deve se preocupar em implementar esses métodos, apenas declarar
suas assinaturas.
Data Transfer Objects - DTOs
Um Data Transfer Object (DTO) é um objeto que
contém dados que serão transferidos entre camadas diferentes, em algum formato
específico.
Às vezes, você deseja transferir dados que não são exatamente um Modelo de
Domínio ou um Objeto de Valor.
Por exemplo, digamos que você esteja desenvolvendo um sistema bancário. Você está implementando um caso de uso que permite ao usuário verificar o saldo
de sua conta.
Portanto, o caso de uso seria algo assim:
- O aplicativo recebe uma solicitação;
- A conta do usuário é carregada de um repositório;
- O aplicativo retorna um objeto contendo o saldo da conta, o carimbo de
data/hora atual, o ID da solicitação e alguns outros dados secundários para fins
de auditoria.
Ao final do processo será retornado um objeto contendo os dados obtidos nesta operação.
Este objeto não tem
comportamento. Ele contém apenas dados e é usado apenas neste caso de uso
como um valor de retorno. Neste cenário este objeto pode ser considerado DTO.
Os DTOs são adequados como objetos com formatos e dados realmente específicos.
Normalmente, você não deve implementá-los querendo reutilizá-los em outros casos
de uso, pois isso uniria os dois casos de uso diferentes.
Camada de infraestrutura
A camada de infraestrutura é a camada mais externa da arquitetura Onion. Ela é
responsável por implementar todas as operações IO que são necessárias para o
software.
Esta camada também pode saber tudo o que está contido nas camadas internas,
podendo importar entidades das camadas de Aplicação e de Domínio.
A camada de infraestrutura não deve implementar nenhuma lógica de negócios,
bem como qualquer fluxo de caso de uso.
Os Repositórios, APIs externas, ouvintes de Eventos e todos os outros códigos
que lidam com IO de alguma forma devem ser implementados nesta camada.
Repositórios
Um Repositório é um padrão para uma coleção de objetos de domínio.
Ele é responsável por lidar com a persistência (como um banco de dados) e
atua como uma coleção de objetos de domínio na memória. Normalmente, cada
agregado de domínio tem seu próprio repositório (se ele deve ser persistido),
então você pode ter um repositório para contas, outro para clientes e assim por
diante.
Normalmente não é uma boa ideia tentar usar um único repositório para mais de um
agregado, porque talvez você acabe tendo um Repositório Genérico.
Na Onion Architecture, o banco de dados é apenas um detalhe da
infraestrutura. O resto do seu código não deve se preocupar se você estiver
armazenando seus dados em um banco de dados, em um arquivo ou apenas na memória.
Camada de apresentação - Views
As partes de seu
código que expõem seu aplicativo para o mundo externo também fazem parte da
camada de infraestrutura, pois lidam com IO.
As camadas internas não devem saber se seu aplicativo está sendo exposto por
meio de uma API, por meio de uma CLI ou qualquer outra coisa.
Vantagens da Onion Architecture
A Onion Architecture, como qualquer padrão, tem suas vantagens e desvantagens.
Vejamos as vantagens:
1-
De fácil manutenção
É mais fácil manter um aplicativo que tenha uma boa separação de interesses.
Você pode alterar as coisas na camada de infraestrutura sem ter que se preocupar
em quebrar uma regra de negócios.
É fácil descobrir onde estão as regras de negócios, os casos de uso, o código
que lida com o banco de dados, o código que expõe uma API e assim por diante.
Além disso, o código é mais fácil de testar devido à injeção de dependência, o
que também contribui para tornar o software mais sustentável.
Linguagem e estrutura independente
A Onion Architecture não depende de nenhuma linguagem ou estrutura específica.
Você pode implementá-lo basicamente em qualquer linguagem que ofereça suporte à
injeção de dependência.
2 - Injeção de
dependência até o fim! Fácil de testar
Ao fazer injeção de dependência em todo o código, tudo se torna mais fácil de
testar.
Em vez de cada módulo ser responsável por instanciar suas próprias dependências,
ele tem suas dependências injetadas durante a inicialização. Dessa forma, quando
você quiser testá-lo, pode apenas injetar um mock que implementa a interface que
seu código está esperando.
Desvantagens
No entanto, como não existe a tal 'bala de prata', existem algumas desvantagens.
1-
É complicado quando você não tem muitas regras de negócios
Quando você está criando um software que não lida com regras de negócios, essa
arquitetura não se ajusta bem. Seria realmente complicado implementar, por
exemplo, um gateway simples usando a Onion Architecture.
Essa arquitetura deve ser usada ao criar serviços que lidam com regras de
negócios. Se não for esse o caso, só desperdiçará seu tempo.
2- Curva de aprendizado
não tão fácil
Pode ser difícil implementar um serviço usando a Onion Architecture quando você
tem um histórico centrado no banco de dados.
A mudança de paradigma não é tão direta, portanto, você precisará investir algum
tempo no aprendizado da arquitetura antes de poder usá-la sem esforço.
Armadilhas para evitar
Existem algumas armadilhas que você deve evitar ao usar esta arquitetura.
Modelos de domínio anêmico
Quando todas as suas regras de negócios estão em serviços de domínio em vez de
em seus modelos de domínio, provavelmente você tem um
Modelo de Domínio Anêmico.
Um modelo de domínio anêmico é um modelo de domínio que não tem comportamento,
apenas dados. Ele atua como um saco de dados, enquanto o próprio comportamento é
implementado em um serviço.
Este anti-padrão tem muitos problemas que são bem descritos no artigo de Fowler.
Observe que os Modelos de Domínio Anêmico são um anti-padrão ao trabalhar em
linguagens OOP, porque, ao executar uma regra de negócios, espera-se que você
altere o estado atual de um objeto de domínio.
Não comece modelando o
banco de dados
Naturalmente, talvez você queira iniciar o desenvolvimento pelo banco de dados,
mas é um erro! Ao trabalhar com a Onion Architecture, você deve sempre começar a
desenvolver as camadas internas antes das externas.
Portanto, você deve começar modelando sua camada de domínio, em vez da camada de
banco de dados. No Onion, o banco de dados é apenas um detalhe.
Seria muito difícil começar pelos repositórios, porque:
- Os repositórios dependem da Camada de Domínio, pois atuam como uma coleção de
objetos de domínio.
- Eles também dependem das interfaces definidas pela Camada de Aplicativo,
portanto, você ainda não sabe quais métodos precisará implementar.
Arquiteturas semelhantes
Existem outras arquiteturas semelhantes que usam alguns dos mesmos princípios.
-
Arquitetura Limpa
- Arquitetura Hexagonal ou Portas e adaptadores
E estamos
conversados...
"Melhor é o que
tarda em irar-se do que o poderoso, e o que controla o seu ânimo do que aquele
que toma uma cidade."
Provérbios 16:32

Referências: