 |
Hoje veremos a diferença básica entre os conceitos de fluxo de dados e da regra de dependência usados na Clean Architecture. |
Vou iniciar repetindo a introdução do meu artigo sobre Clean Architecture.
E o que é
Clean Architecture ?
A
Arquitetura limpa refere-se à organização do projeto de forma que seja fácil de
entender e fácil de mudar conforme o projeto cresce. Isso não acontece por
acaso. É preciso um planejamento intencional para que isso ocorra.
O segredo para construir um grande projeto que seja fácil de manter é este:
- Separar os arquivos ou classes em componentes que podem mudar independentemente de outros componentes.
Vamos ilustrar isso com algumas imagens. Vamos iniciar com uma imagem onde vamos representar o domínio e a infraestrutura da aplicação.
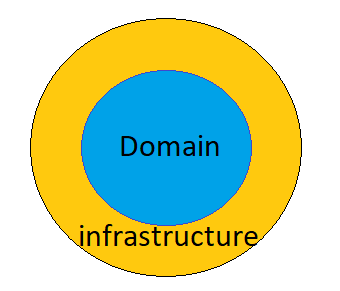
No círculo interno temos a camada de domínio da aplicação. É aqui que você coloca as regras de negócios que representa a alma do seu aplicativo, a funcionalidade central do seu projeto.
O círculo externo
é onde esta a infraestrutura. Aqui você inclui a
interface com o usuário (UI), o banco de dados, as APIs da web e frameworks.
Essas coisas têm mais probabilidade de mudar do que o domínio. Por exemplo, é
mais provável que você mude a aparência de um botão na interface do que mudar
uma regra do seu negócio.
Uma fronteira entre o domínio e a infraestrutura é configurada de forma que o
domínio não saiba nada sobre a infraestrutura. Isso significa que a IU e o banco
de dados dependem das regras de negócios, mas as regras de negócios não dependem
da IU ou do banco de dados.
Não importa se a IU é uma interface web, um aplicativo desktop ou um aplicativo mobile. Não importa se os dados são armazenados usando SQL Server, MySQL ou NoSQL ou na nuvem. O domínio não se importa. Isso torna mais fácil mudar a infraestrutura.
A seguir vamos usar outra imagem para definir alguns termos com mais detalhes:
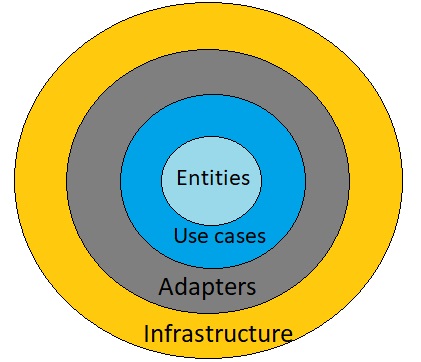
Agora a camada de domínio foi subdividida em Entidades e Casos de uso, e uma camada adaptadora (Adapters) forma a fronteira entre o domínio e a camada de infraestrutura.
Dessa forma ao iniciar um projeto, você deve primeiro trabalhar nas regras de negócios. Todas as outras coisas são detalhes. O banco de dados é um detalhe. A UI é um detalhe. O SO é um detalhe. Uma web API é um detalhe. Uma framework é um detalhe.
Os componentes da regra de
negócios são mais estáveis e não devem saber nada sobre
os componentes de infraestrutura que são mais voláteis,
os que lidam com a interface do usuário, o banco de
dados, web, frameworks e outros detalhes.
O limite entre as camadas de componentes é mantido
usando adaptadores de interface que traduzem os
dados entre as camadas e mantêm as dependências
apontando na direção dos componentes internos mais
estáveis.
O Fluxo de dados
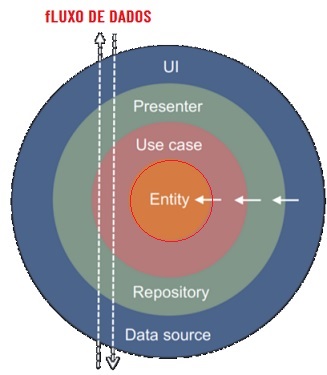
Vamos começar explicando o fluxo
de dados na Clean Architecture
com um exemplo.
Imagine abrir um aplicativo que carrega uma lista de
postagens que contém informações adicionais do usuário.
O fluxo de dados seria o seguinte:
1. A camada de interface ou IU chama o método do
Presenter/ViewModel.
2. A camada Presenter/ViewModel
executa o caso de uso;
3. O Use Cases combina dados do usuário e
repositórios;
4. Cada Repositório retorna dados de uma fonte de dados;
5. As informações fluem de volta para a camada de
interface, onde exibimos a lista de postagens;
No exemplo acima, podemos ver como a ação do usuário
flui da IU até a fonte de dados e, em seguida, flui de
volta para baixo.
Este fluxo de dados não é o mesmo que a regra de dependência.
Vamos conferir...
A Regra de dependência
A figura a seguir mostra as camadas que fazem parte da Clean Architecture:
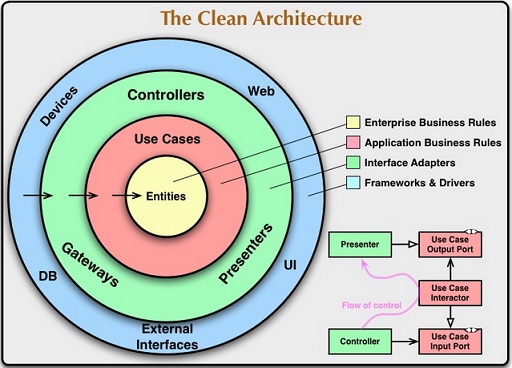
Os círculos concêntricos da
representam diferentes áreas do software. Em geral,
quanto mais você avança, de mais alto nível se torna o
software. Os círculos externos são mecanismos. Os
círculos internos são políticas.
A regra que faz essa arquitetura funcionar é a regra de
dependência:
"As dependências do código-fonte devem apontar apenas
para dentro, em direção a políticas de nível superior."
Nada em um círculo interno pode saber absolutamente nada
sobre algo em um círculo externo. Em particular, o nome
de algo declarado em um círculo externo não deve ser
mencionado pelo código em um círculo interno. Isso
inclui funções, classes, variáveis ou qualquer outra
entidade de software nomeada.
Da mesma forma, os formatos de dados declarados em um
círculo externo não devem ser usados por um círculo
interno, especialmente se esses formatos forem gerados
por uma estrutura em um círculo externo. Não queremos
que nada em um círculo externo afete os círculos
internos.
Podemos inverter a figura para poder identificar melhor
as camadas e as fronteiras entre elas:
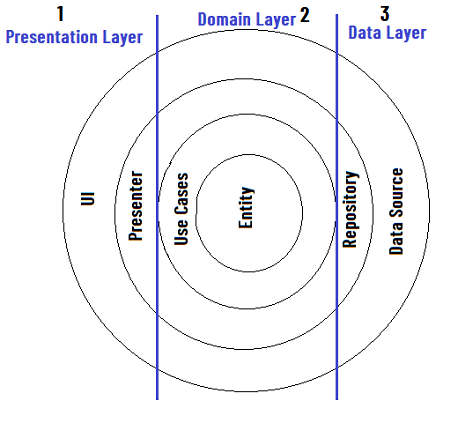
Identificando as diferentes camadas e limites entre elas temos que :
- A
camada de apresentação contém a interface com o
usuário, UI, que são coordenadas por Apresentadores/ ViewModels que executam um ou vários casos de uso. A camada de apresentação
depende da camada de domínio;
- A
camada de domínio é a parte mais interna da
cebola (sem dependências com outras camadas) e contém entidades,
casos de uso e interfaces de repositório. Os casos de uso combinam dados de
uma ou várias interfaces de repositório;
- A camada de dados contém implementações de repositório e uma ou várias fontes de dados. Os repositórios são responsáveis por coordenar os dados das diferentes fontes de dados. A camada de dados depende da camada de domínio;
A camada de
domínio está no centro da cebola, o que significa que é o núcleo do nosso
programa. Esta é uma das principais razões pelas quais não deve haver nenhuma
dependência com outras camadas.
A apresentação e as camadas de dados são menos importantes, pois são apenas
implementações que podem ser facilmente substituídas. Quanto mais exterior
for na cebola, as coisas mais prováveis tendem a mudar.
Um dos erros mais
comuns é ter seu aplicativo dirigido por sua camada de dados/sistema de dados
específico tornando difícil substituir ou fazer a ponte com diferentes fontes de
dados no futuro.
Assim a camada de domínio NÃO depende da camada de dados nem da camada de
apresentação conforme mostra a figura abaixo:
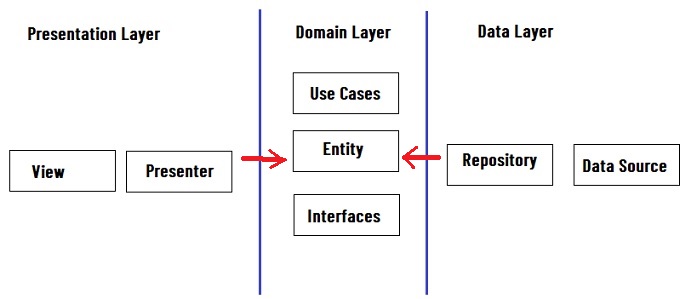
Dessa forma possui módulos com as regras de dependência corretas significa que nosso Domínio não tem dependência de nenhuma outra camada.
"E, ao pôr do
sol, todos os que tinham enfermos de várias doenças lhos traziam; e, pondo as
mãos sobre cada um deles, 'Jesus' os curava."
Lucas 4:40

Referências:
-
ASP .NET Core - Iniciando com o Blazor
-
ASP .NET Core - CRUD usando Blazor e Entity ...
-
Blazor - O novo framework SPA da Microsoft -
-
Visual Studio Code - Suporte ao desenvolvimento Blazor
-
ASP .NET Core - Implementando Clean Architecture - I
-
ASP .NET Core - Clean Architecture
-
ASP .NET Core - Usando uma arquitetura Clean Code
-
Clean Architecture Essencial - ASP .NET Core com C# | Udemy